初学者DataStage教程:IBM DataStage(ETL工具)培训
什么是DataStage?
DataStage是一种ETL工具,用于从源到目标提取、转换和加载数据。这些数据的来源可能包括顺序文件、索引文件、关系数据库、外部数据源、存档、企业应用程序等。DataStage通过提供高质量的数据来促进业务分析,以帮助获得业务智能。
DataStage ETL工具在大型组织中用作不同系统之间的接口。它负责将数据从源提取、转换和加载到目标。它最初于90年代中期由VMark推出。在IBM于2005年收购DataStage后,它被更名为IBM WebSphere DataStage,后来又更名为IBM InfoSphere。
到目前为止,市场上可用的Datastage各种版本有企业版(PX)、服务器版、MVS版、用于PeopleSoft的DataStage等。最新版本是IBM InfoSphere DataStage。
IBM Information Server包含以下产品,
- IBM InfoSphere DataStage
- IBM InfoSphere QualityStage
- IBM InfoSphere Information Services Director
- IBM InfoSphere Information Analyzer
- IBM Information Server FastTrack
- IBM InfoSphere Business Glossary
DataStage概述
Datastage具有以下能力。
- 它可以集成来自最广泛的企业和外部数据源的数据
- 实施数据验证规则
- 它对于处理和转换大量数据很有用
- 它使用可扩展的并行处理方法
- 它可以处理复杂的转换并管理多个集成过程
- 利用直接连接企业应用程序作为源或目标
- 利用元数据进行分析和维护
- 以批处理、实时或Web服务方式运行
在本DataStage教程的以下章节中,我们将简要描述IBM InfoSphere DataStage的以下方面
- 数据转换
- 作业
- 并行处理
InfoSphere DataStage和QualityStage可以访问企业应用程序和数据源中的数据,例如
- 关系数据库
- 大型机数据库
- 业务和分析应用程序
- 企业资源计划(ERP)或客户关系管理(CRM)数据库
- 在线分析处理(OLAP)或绩效管理数据库
处理阶段类型
IBM infosphere作业由单独的阶段组成,这些阶段链接在一起。它描述了数据从数据源到数据目标的流程。通常,一个阶段至少有一个数据输入和/或一个数据输出。但是,一些阶段可以接受多个数据输入并输出到多个阶段。
在作业设计中,可以使用各种阶段
- 转换阶段
- 过滤器阶段
- 聚合器阶段
- 删除重复项阶段
- 连接阶段
- 查找阶段
- 复制阶段
- 排序阶段
- 容器
DataStage组件和架构
Datastage有四个主要组件,即,
- 管理员:用于管理任务。这包括设置DataStage用户、设置清除标准以及创建和移动项目。
- 管理器:它是ETL DataStage存储库的主要接口。它用于存储和管理可重用的元数据。通过DataStage管理器,可以查看和编辑存储库的内容。
- 设计器:用于创建DataStage应用程序或作业的设计界面。它指定数据源、所需转换以及数据目的地。作业被编译以创建可执行文件,这些可执行文件由Director调度并由Server运行
- Director:用于验证、调度、执行和监控DataStage服务器作业和并行作业。
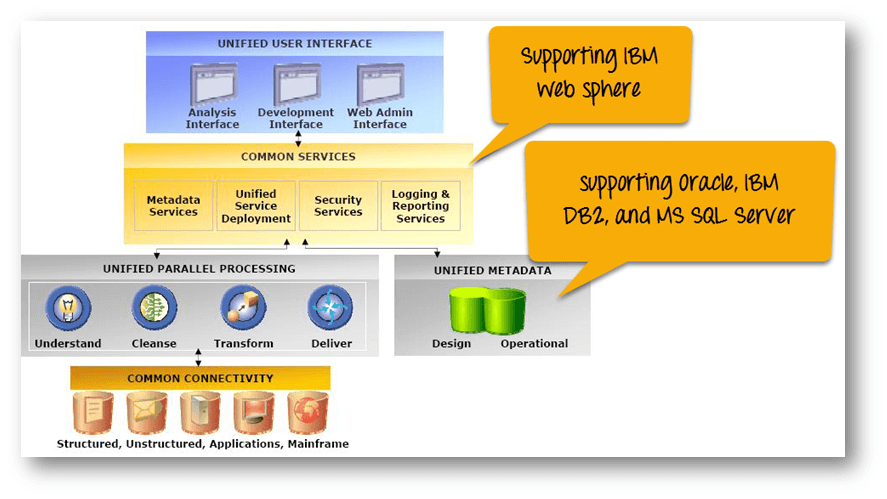
上图说明了IBM Infosphere DataStage如何与IBM Information Server平台上的其他元素进行交互。DataStage分为两部分:共享组件和运行时架构。
|
共享 |
统一的用户界面 |
|
|
通用服务 |
|
|
|
通用并行处理 |
|
|
|
运行时架构 |
OSH脚本 |
|
Datastage工具先决条件
对于DataStage,您将需要以下设置。
- Infosphere
- DataStage Server 9.1.2或更高版本
- Microsoft Visual Studio .NET 2010 Express Edition C++
- Oracle客户端(完整客户端,不是即时客户端),如果连接到Oracle数据库
- DB2客户端,如果连接到DB2数据库
现在,在本DataStage初学者教程系列中,我们将学习如何下载和安装InfoSphere Information Server。
下载和安装InfoSphere Information Server
要访问DataStage,请下载并安装最新版本的IBM InfoSphere Server。该服务器支持AIX、Linux和Windows操作系统。您可以根据需要选择。
要将数据从旧版本infosphere迁移到新版本,请使用资产互换工具。
安装文件
要安装和配置Infosphere Datastage,您的设置中必须包含以下文件。
对于Windows,
- EtlDeploymentPackage-windows-oracle.pkg
- EtlDeploymentPackage-windows-db2.pkg
对于Linux,
- EtlDeploymentPackage-linux-db2.pkg
- EtlDeploymentPackage-linux-oracle.pkg
CDC事务阶段作业中更改数据的过程流
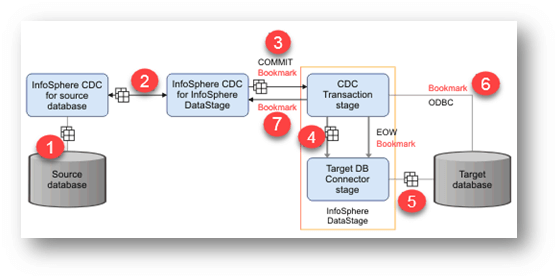
- 数据库的“InfoSphere CDC”服务会监控并捕获源数据库的更改。
- 根据复制定义,“InfoSphere CDC”会将更改数据传输到“InfoSphere CDC for InfoSphere DataStage”。
- “InfoSphere CDC for InfoSphere DataStage”服务器通过TCP/IP会话将数据发送到“CDC事务阶段”。“InfoSphere CDC for InfoSphere DataStage”服务器还发送一个COMMIT消息(以及书签信息),以标记捕获日志中的事务边界。
- 对于“InfoSphere CDC for InfoSphere DataStage”服务器发送的每个COMMIT消息,“CDC事务阶段”会创建波次结束(EOW)标记。这些标记会通过所有输出链接发送到目标数据库连接器阶段。
- 当“目标数据库连接器阶段”在所有输入链接上接收到波次结束标记时,它会将书签信息写入书签表,然后将事务提交到目标数据库。
- “InfoSphere CDC for InfoSphere DataStage”服务器从“目标数据库”的书签表中请求书签信息。
- “InfoSphere CDC for InfoSphere DataStage”服务器接收到书签信息。
这些信息用于:
- 确定复制开始时要从事务日志中读取更改的起始点。
- 确定是否可以清理现有事务日志。
设置SQL复制
在开始Datastage之前,您需要设置数据库。您将创建两个DB2数据库。
- 一个作为复制源,
- 一个作为目标。
您还将创建两个表(Product和Inventory)并用示例数据填充它们。然后,您可以测试SQL复制和Datastage之间的集成。
接下来,您将通过创建控制表、订阅集、注册和订阅集成员来设置SQL复制。我们将在下一节中更详细地学习。
在这里,我们将以零售销售项为例作为我们的数据库,并创建Product和Inventory这两个表。这些表将通过这些集合将数据从源加载到目标。(控制表、订阅集、注册和订阅集成员。)
第1步)创建一个名为SALES的源数据库。在该数据库下,创建两个表product和Inventory。
第2步)运行以下命令创建SALES数据库。
db2 create database SALES
第3步)为SALES数据库开启归档日志记录。此外,使用以下命令备份数据库。
db2 update db cfg for SALES using LOGARCHMETH3 LOGRETAIN db2 backup db SALES
第4步)在同一个命令提示符下,切换到从下载的压缩文件中提取的sqlrepl-datastage-tutorial目录下的setupDB子目录。
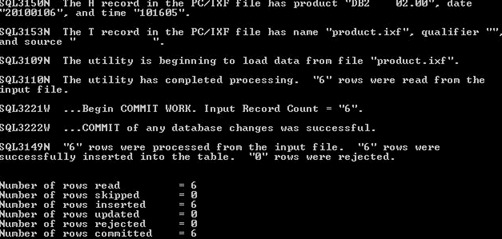
第5步)使用以下命令创建Inventory表,并通过运行以下命令将数据导入表。
db2 import from inventory.ixf of ixf create into inventory
第6步)创建一个目标表。将目标数据库命名为STAGEDB。
既然您已经创建了源数据库和目标数据库,那么在本DataStage教程中的下一步,我们将了解如何复制它。
以下信息可能有助于设置ODBC数据源。
创建SQL复制对象
下图显示了更改数据如何从源传递到目标数据库。您创建表之间的源到目标映射,称为订阅集成员,并将成员分组到订阅中。
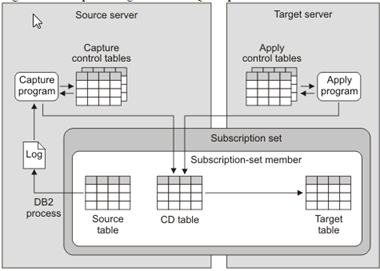
InfoSphere CDC(更改数据捕获)中的复制单元称为订阅。
- 源中的更改被捕获在“Capture control table”中,然后发送到CD表,再发送到目标表。而apply程序将包含需要进行更改的行的详细信息。它还将加入订阅集中的CD表。
- 订阅包含映射详细信息,这些详细信息指定如何将源数据存储中的数据应用于目标数据存储。请注意,CDC现在被称为Infosphere data replication。
- 当订阅执行时,InfoSphere CDC会捕获源数据库上的更改。InfoSphere CDC将更改数据传递到目标,并将同步点信息存储在目标数据库的书签表中。
- InfoSphere CDC使用书签信息来监控InfoSphere DataStage作业的进度。
- 在发生故障时,书签信息用作重新启动点。在我们的示例中,ASN.IBMSNAP_FEEDETL表存储了与DataStage相关的同步点信息,用于跟踪DataStage的进度。
在本IBM DataStage培训教程的这一部分,您需要执行以下操作:
- 创建CAPTURE CONTROL表和APPLY CONTROL表来存储复制选项。
- 将PRODUCT和INVENTORY表注册为复制源。
- 创建包含两个成员的订阅集。
- 创建订阅集成员和目标CCD表。
使用ASNCLP命令行程序设置SQL复制。
第1步)在sqlrepl-datastage-tutorial/setupSQLRep目录中找到crtCtlTablesCaptureServer.asnclp脚本文件。
第2步)在文件中,将<db2-connect-ID>和“<password>”替换为您连接SALES数据库的用户ID和密码。
第3步)切换到sqlrepl-datastage-tutorial/setupSQLRep目录,然后运行脚本。使用以下命令。该命令将连接到SALES数据库,生成一个SQL脚本来创建Capture控制表。
asnclp –f crtCtlTablesCaptureServer.asnclp
第4步)在同一目录中找到crtCtlTablesApplyCtlServer.asnclp脚本文件。现在,将<db2-connect-ID>和“<password>”的两个实例替换为您连接STAGEDB数据库的用户ID和密码。
第5步)现在,在同一个命令提示符下,使用以下命令创建apply控制表。
asnclp –f crtCtlTablesApplyCtlServer.asnclp
第6步)找到crtRegistration.asnclp脚本文件,并替换所有<db2-connect-ID>实例为您连接SALES数据库的用户ID。同时,将“<password>”更改为连接密码。
第7步)要注册源表,请使用以下脚本。作为创建注册的一部分,ASNCLP程序将创建两个CD表。CDPRODUCT和CDINVENTORY。
asnclp –f crtRegistration.asnclp
CREATE REGISTRATION命令使用以下选项:
- 差异刷新:提示Apply程序仅在源表中的行发生更改时更新目标表。
- 全部镜像:此选项用于注册更改发生之前源列中的值,以及更改发生之后的值。
第8步)要连接到目标数据库(STAGEDB),请使用以下步骤。
- 找到crtTableSpaceApply.bat文件,用文本编辑器打开它。
- 将<stagedb-connect-ID>和<stagedb-password>替换为用户ID和密码。
- 在DB2命令窗口中,输入crtTableSpaceApply.bat并运行文件。
- 此批处理文件将在目标数据库(STAGEDB)上创建一个新的表空间。
第9步)找到crtSubscriptionSetAndAddMembers.asnclp脚本文件,并进行以下更改。
- 替换所有<sales-connect-ID>和<sales-password>实例为您连接SALES数据库(源)的用户ID和密码。
- 替换所有<stagedb-connect-ID>和<stagedb-password>实例为您连接STAGEDB数据库(目标)的用户ID。
更改后,运行脚本以创建订阅集(ST00),该订阅集将源表和目标表分组。该脚本还在目标数据库中创建两个订阅集成员和CCD(一致性更改数据),用于存储修改后的数据。这些数据将由Infosphere DataStage使用。
第10步)运行脚本以创建订阅集、订阅集成员和CCD表。
asnclp –f crtSubscriptionSetAndAddMembers.asnclp
用于创建订阅集和两个成员的各种选项包括:
- 完整(Condensed Off)
- 外部
- 加载类型:导入导出
- 计时:连续
第11步)由于复制管理工具中存在缺陷,您需要执行另一个批处理文件,将IBMSNAP_SUBS_SET控制表中的TARGET_CAPTURE_SCHEMA列设置为null。
- 找到updateTgtCapSchema.bat文件。用文本编辑器打开它。将<stagedb-connect-ID>和<stagedb-password>替换为您连接STAGEDB数据库的用户ID。
- 在DB2命令窗口中,输入命令updateTgtCapSchema.bat并执行该文件。
创建映射CCD表到DataStage的定义文件
在我们下一步进行复制之前,我们需要将CCD表与DataStage连接。在本节中,我们将了解如何将SQL与DataStage连接。
要将CCD表与DataStage连接,您需要创建Datastage定义(.dxs)文件。.dsx文件的格式由DataStage用于导入和导出作业定义。您将使用ASNCLP脚本创建两个.dsx文件。例如,我们在此创建了两个.dsx文件。
- stagedb_AQ00_SET00_sJobs.dsx:创建一个作业序列,该序列控制四个并行作业的工作流程。
- stagedb_AQ00_SET00_pJobs.dsx:创建四个并行作业。
ASNCLP程序会自动将CCD列映射到Datastage列格式。这仅在ASNCLP在Windows、Linux或Unix过程中运行时才受支持。
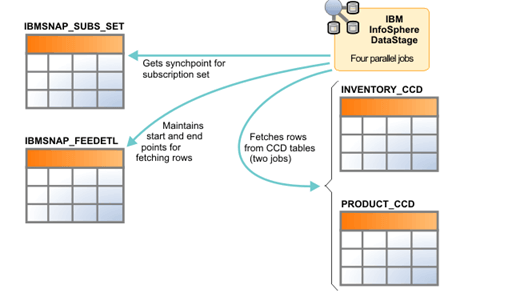
Datastage作业从CCD表中提取行。
- 一个作业设置一个同步点,DataStage在那里停止从两个表中提取数据。该作业通过从IBMSNAP_SUBS_SET表中选择ST00订阅集的SYNCHPOINT值并将其插入IBMSNAP_FEEDETL表的MAX_SYNCHPOINT列来获取此信息。
- 从PRODUCT_CCD和INVENTORY_CCD表中提取数据的两个作业。作业通过从IBMSNAP_FEEDETL表中选择订阅集的MIN_SYNCHPOINT和MAX_SYNCHPOINT值来知道从哪些行开始提取。
启动复制
要启动复制,您将使用以下步骤。当CCD表填充数据时,表示复制设置已验证。要查看目标CCD表中复制的数据,请使用DB2 Control Center图形用户界面。
第1步)确保DB2正在运行,如果未运行,请使用db2 start命令。
第2步)然后,从操作系统提示符使用asncap命令启动捕获程序。例如。
asncap capture_server=SALES
以上命令将SALES数据库指定为Capture服务器。在捕获运行时,保持命令窗口打开。
第3步)现在打开一个新的命令提示符。然后使用asnapply命令启动APPLY程序。
asnapply control_server=STAGEDB apply_qual=AQ00

- 该命令指定STAGEDB数据库作为Apply控制服务器(包含Apply控制表的数据库)。
- AQ00作为Apply限定符(此控制表集标识符)。
Leave command window open with Apply is running.(保持命令窗口打开,Apply正在运行。)
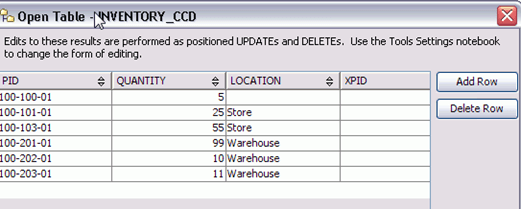
第4步)现在打开另一个命令提示符,并发出db2cc命令启动DB2 Control Center。接受默认的Control Center。
第5步)现在,在左侧导航树中,展开All Databases > STAGEDB,然后单击Tables。双击表名(Product CCD)以打开表。它看起来会像这样。
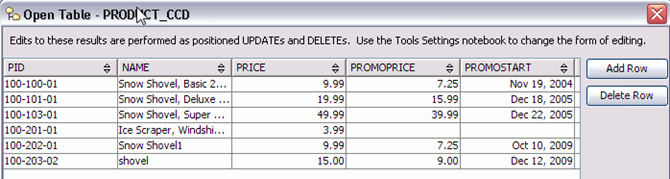
同样,您也可以打开INVENTORY的CCD表。
如何在Datastage工具中创建项目
首先,您将在DataStage中创建一个项目。为此,您必须是InfoSphere DataStage管理员。
安装和复制完成后,您需要创建一个项目。在DataStage中,项目是组织数据的方法。它包括在特定项目中定义数据文件、阶段和构建作业。
要创建DataStage项目,请按照以下步骤操作:
步骤1)启动DataStage软件
启动DataStage和QualityStage Administrator。然后单击Start > All programs > IBM Information Server > IBM WebSphere DataStage and QualityStage Administrator。
步骤2)连接DataStage服务器和客户端
要从DataStage客户端连接到DataStage服务器,请输入域名称、用户ID、密码和服务器信息等详细信息。
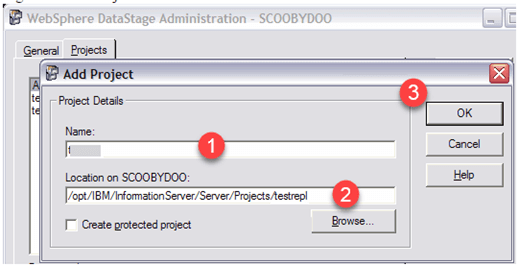
步骤3)添加新项目
在WebSphere DataStage Administration窗口中。单击Projects选项卡,然后单击Add。
步骤4)输入项目详细信息
在WebSphere DataStage Administration窗口中,输入以下详细信息:
- 名称
- 文件位置
- 点击“确定”
每个项目包含:
- DataStage作业
- 内置组件。这些是在作业中使用的预定义组件。
- 用户定义的组件。这些是使用DataStage Manager或DataStage Designer创建的自定义组件。
我们将介绍如何导入复制作业到Datastage Infosphere。
如何在Datastage和QualityStage Designer中导入复制作业
您将在IBM InfoSphere DataStage和QualityStage Designer客户端中导入作业。并在IBM InfoSphere DataStage和QualityStage Director客户端中执行它们。
Designer客户端就像一个空白画布,用于构建作业。它提取、转换、加载和检查数据质量。它提供了构成作业基本构建块的工具。它包括:
- 阶段:它连接到数据源以读取或写入文件并处理数据。
- 链接:它连接阶段,数据沿其流动。
InfoSphere DataStage和QualityStage Designer客户端中的阶段存储在Designer工具面板中。
InfoSphere QualityStage包含以下阶段:
- Investigate阶段
- Standardize阶段
- Match Frequency阶段
- One-source Match阶段
- Two-source Match阶段
- Survive阶段
- Standardization Quality Assessment (SQA)阶段
您可以在DataStage infosphere中创建4种类型的作业。
- 并行作业
- 序列作业
- 大型机作业
- 服务器作业
让我们一步一步地介绍如何导入复制作业文件。
第1步)启动DataStage和QualityStage Designer。单击Start > All programs > IBM Information Server > IBM WebSphere DataStage and QualityStage Designer
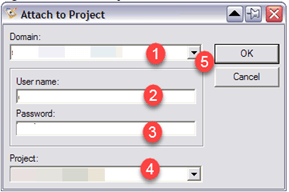
第2步)在Attach to Project窗口中,输入以下详细信息。
- 领域
- 用户名
- 密码
- 项目名称
- 确定
第3步)然后,从File菜单中单击import -> DataStage Components。
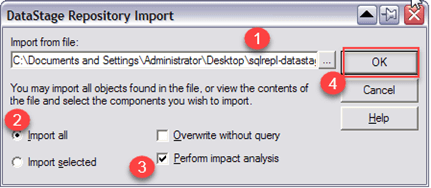
将打开一个新的DataStage Repository Import窗口。
- 在此窗口中,浏览我们之前创建的STAGEDB_AQ00_ST00_sJobs.dsx文件。
- 选择“Import all.”选项。
- 勾选“Perform Impact Analysis.”复选框。
- 单击‘OK’。
作业导入后,DataStage将创建STAGEDB_AQ00_ST00_sequence作业。
第4步)遵循相同的步骤导入STAGEDB_AQ00_ST00_pJobs.dsx文件。此导入将创建四个并行作业。
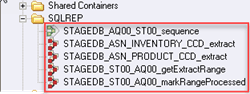
第5步)在Designer Repository窗格下->打开SQLREP文件夹。在文件夹内,您将看到Sequence Job和四个并行作业。
第6步)要查看序列作业。转到存储库树,右键单击STAGEDB_AQ00_ST00_sequence作业,然后单击Edit。它将显示作业序列控制的四个并行作业的工作流程。
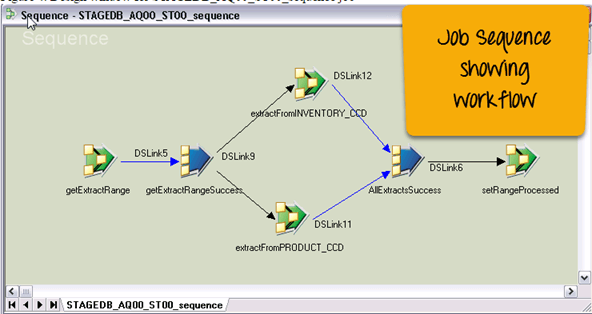
每个图标是一个阶段,
- getExtractRange阶段:它更新IBMSNAP_FEEDETL表。它将数据提取的起始点设置为DataStage上次提取行的点,并将结束点设置为订阅集处理的最后一个事务。
- getExtractRangeSuccess:此阶段将起始点馈送到extractFromINVENTORY_CCD阶段和extractFromPRODUCT_CCD阶段。
- AllExtractsSuccess:此阶段确保extractFromINVENTORY_CCD和extractFromPRODUCT_CCD都成功完成。然后将提取的最后一行同步点传递给setRangeProcessed阶段。
- setRangeProcessed阶段:它更新IBMSNAP_FEEDETL表。以便DataStage知道从哪里开始下一轮数据提取。
第7步)要查看并行作业。右键单击STAGEDB_ASN_INVENTORY_CCD,然后在存储库下选择edit。它将打开如下所示的窗口。
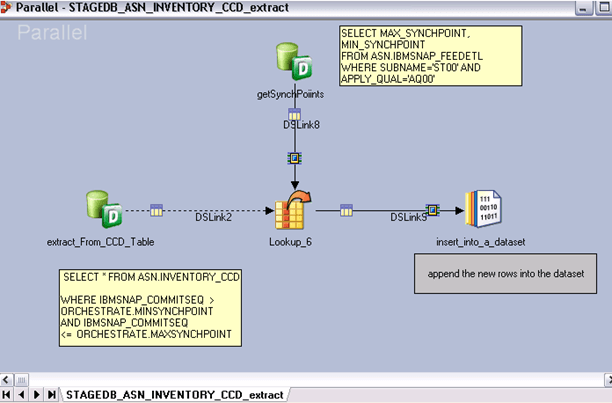
在上图所示,您可以看到来自Inventory CCD表的数据和来自FEEDETL表的同步点详细信息被渲染到Lookup_6阶段。
创建从DataStage到STAGEDB数据库的数据连接
下一步是建立InfoSphere DataStage和SQL复制目标数据库之间的数据连接。它包含CCD表。
在DataStage中,您可以使用数据连接对象和相关的连接器阶段来快速定义作业设计中到数据源的连接。
第1步)STAGEDB包含DataStage用于同步其数据提取的应用控制表以及从中提取数据的CCD表。使用以下命令。
db2 catalog tcpip node SQLREP remote ip_address server 50000 db2 catalog database STAGEDB as STAGEDB2 at node SQLREP
注意:STAGEDB创建的系统的IP地址。
第2步)单击File > New > Other > Data Connection。
第3步)您将看到一个带有两个选项卡:Parameters和General的窗口。
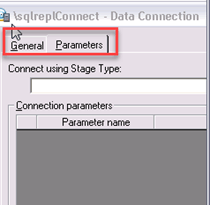
步骤 4) 在此步骤中,
- 在General选项卡中,将数据连接命名为sqlreplConnect。
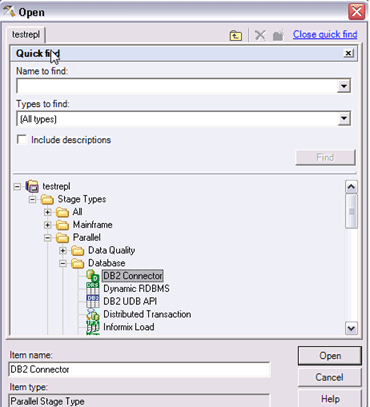
- 在Parameters选项卡中,如下图所示:
- 单击“Connect using Stage Type”字段旁边的浏览按钮,然后在
- Open窗口中,将存储库树导航到Stage Types –> Parallel – > Database —-> DB2 Connector。
- 单击Open。
第5步)在Connection parameters表中,输入以下详细信息:
- ConnectionString:STAGEDB2
- Username:连接STAGEDB数据库的用户ID。
- Password:连接STAGEDB数据库的密码。
- Instance:包含STAGEDB数据库的DB2实例名称。
第6步)在下一个窗口中保存数据连接。单击“save”按钮。
将表定义导入DataStage中的STAGEDB
在上一步中,我们已经看到InfoSphere DataStage和STAGEDB数据库已连接。现在,将PRODUCT_CCD和INVENTORY_CCD表的列定义和其他元数据导入Information Server存储库。
在designer窗口中,请遵循以下步骤。
第1步)选择Import > Table Definitions > Start Connector Import Wizard。
第2步)从向导的connector selection页面,选择DB2 Connector,然后单击Next。
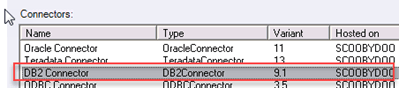
第3步)在connection detail页面上单击load。这将使用您在上一个章节中创建的数据连接的连接信息填充向导字段。
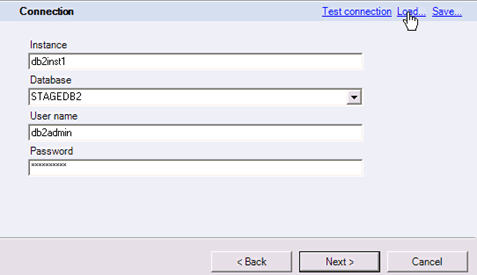
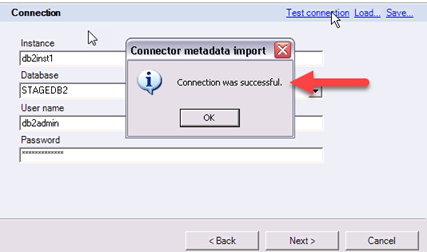
第4步)在同一页面上单击Test connection。这将提示DataStage尝试连接到STAGEDB数据库。您可以看到消息“connection is successful”。单击Next。
第5步)确保在Data source location页面上,Hostname和Database name字段已正确填充。然后单击next。
第6步)在Schema页面上。输入Apply控制表的模式(ASN)或检查ASN模式是否已预填充到模式字段中。然后单击next。Selection页面将显示ASN模式中定义的表列表。
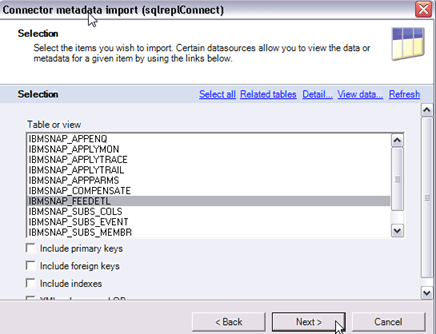
第7步)我们需要从中导入元数据的第一张表是IBMSNAP_FEEDETL,这是一个Apply控制表。它包含同步点信息,允许DataStage跟踪它已从CCD表中提取了哪些行。选择IBMSNAP_FEEDETL,然后单击Next。
第8步)要完成IBMSNAP_FEEDETL表的定义导入。单击import,然后在打开的窗口中单击open。
第9步)重复步骤1-8两次,以导入PRODUCT_CCD表的定义,然后是INVENTORY_CCD表的定义。
注意:在导入inventory和product的定义时,请确保将模式从ASN更改为PRODUCT_CCD和INVENTORY_CCD创建的模式。
现在DataStage拥有连接到SQL复制目标数据库所需的所有详细信息。
设置DataStage作业的属性
对于我们拥有的四个DataStage并行作业中的每一个,它们都包含一个或多个连接到STAGEDB数据库的阶段。您需要修改阶段以添加连接信息并链接到DataStage填充的数据集文件。
阶段具有可编辑的预定义属性。在这里,我们将更改STAGEDB_ASN_PRODUCT_CCD_extract并行作业的某些属性。
第1步)浏览Designer存储库树。在SQLREP文件夹下,选择STAGEDB_ASN_PRODUCT_CCD_extract并行作业。要进行编辑,请右键单击作业。并行作业的设计窗口将在Designer Palette中打开。
第2步)找到绿色的图标。此图标表示DB2连接器阶段。它用于从CCD表提取数据。双击该图标。将打开一个阶段编辑器窗口。

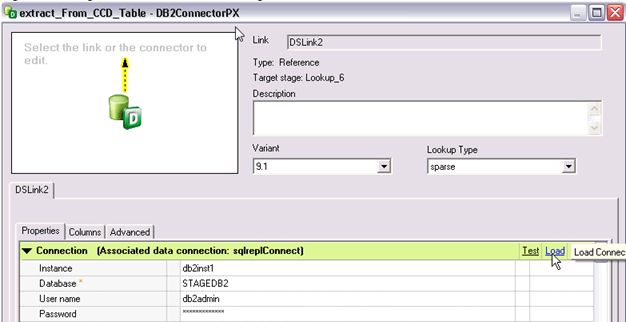
第3步)在编辑器中,单击Load以使用连接信息填充字段。要关闭阶段编辑器并保存更改,请单击OK。
第4步)现在返回到STAGEDB_ASN_PRODUCT_CCD_extract并行作业的设计窗口。找到getSynchPoints DB2连接器阶段的图标。然后双击该图标。
第5步)现在单击load按钮以使用连接信息填充字段。
注意:如果您使用的数据库不是STAGEDB作为Apply控制服务器。那么,选择用于加载getSynchPoints阶段的连接信息的选项,该阶段与控制表而不是CCD表进行交互。
步骤 6) 在此步骤中,
- 在运行InfoSphere DataStage的系统上创建一个空文本文件。
- 将此文件命名为productdataset.ds,并记下您保存它的位置。
- DataStage在获取CCD表中的更改后,会将更改写入此文件。
- 用于在链接作业之间移动数据的持久数据集或文件称为持久数据集。它由DataSet阶段表示。
第7步)现在打开设计窗口中的阶段编辑器,双击insert_into_a_dataset图标。它将打开另一个窗口。

第8步)在此窗口中,
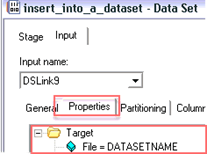
- 在properties选项卡下,确保Target文件夹已打开,并且File = DATASETNAME属性已高亮显示。
- 在右侧,您将有一个文件字段。
- 输入productdataset.ds文件的完整路径。
- 点击“确定”。
您现在已经更新了产品CCD表的 所有必需属性。关闭设计窗口并保存所有更改。
第9步)现在,从Designer的存储库窗格中找到并打开STAGEDB_ASN_INVENTORY_CCD_extract并行作业。重复步骤3-8。
注意:
- 如果您的控制服务器不是STAGEDB,则需要为getSynchPoints阶段加载控制服务器数据库的连接信息到阶段编辑器。
- 对于STAGEDB_ST00_AQ00_getExtractRange和STAGEDB_ST00_AQ00_markRangeProcessed并行作业,打开所有DB2连接器阶段。然后使用load函数添加STAGEDB数据库的连接信息。
编译和运行DataStage作业
当DataStage作业准备好编译时,Designer通过查看输入、转换、表达式和其他详细信息来验证作业的设计。
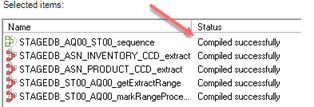
作业编译成功后,即可运行。我们将编译所有五个作业,但只会运行“作业序列”。这是因为该作业控制着所有四个并行作业。
第1步)在SQLREP文件夹下。通过(Ctrl+Shift)选择所有五个作业。然后右键单击并选择Multiple job compile选项。
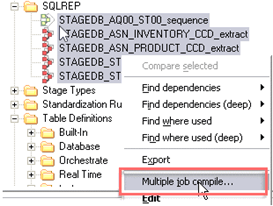
第2步)您将在DataStage Compilation Wizard中看到五个选定的作业。单击Next。
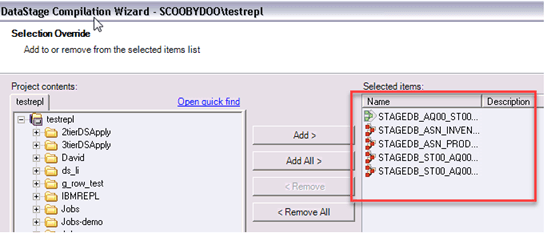
第3步)编译开始,并显示“Compiled successfully”消息。
第4步)现在启动DataStage和QualityStage Director。选择Start > All programs > IBM Information Server > IBM WebSphere DataStage and QualityStage Director。
第5步)在左侧的项目导航窗格中。单击SQLREP文件夹。这将把所有五个作业带到Director状态表中。
第6步)选择STAGEDB_AQ00_S00_sequence作业。从菜单栏单击Job > Run Now。
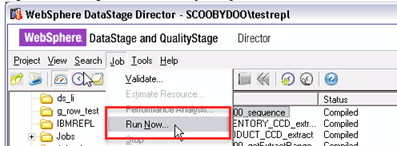
编译完成后,您将看到完成状态。
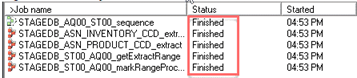
现在检查是否已将存储在PRODUCT_CCD和INVENTORY_CCD表中的已更改行提取到两个数据集文件中。
第7步)返回Designer并打开STAGEDB_ASN_PRODUCT_CCD_extract作业。要打开阶段编辑器,请双击insert_into_a_dataset图标。然后单击view data。
第8步)接受rows to be displayed窗口中的默认设置。然后单击OK。将打开一个数据浏览器窗口来显示数据集文件的内容。
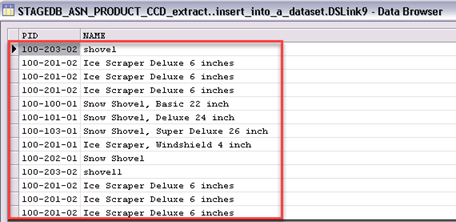
测试SQL复制和DataStage之间的集成
在上一步中,我们编译并执行了作业。在本节中,我们将检查SQL复制和DataStage的集成。为此,我们将修改源表,看看相同的更改是否已更新到DataStage。
第1步)导航到适用于您操作系统的sqlrepl-datastage-scripts文件夹。
第2步)按照以下步骤启动SQL复制。
- 运行startSQLCapture.bat(Windows)文件以在SALES数据库启动Capture程序。
- 运行startSQLApply.bat(Windows)文件以在STAGEDB数据库启动Apply程序。
第3步)现在打开updateSourceTables.sql文件。要连接到SALES数据库,请将<sales-connect-ID>和<sales-password>替换为用户ID和密码。
第4步)打开DB2命令窗口。将目录更改为sqlrepl-datastage-tutorial\scripts,然后运行给定的命令。
db2 -tvf updateSourceTables.sql
SQL脚本将在Sales数据库中的Product和Inventory两个表上执行Update、Insert和Delete等各种操作。
第5步)在运行DataStage的系统上。打开DataStage Director并执行STAGEDB_AQ00_S00_sequence作业。单击Job > Run Now。
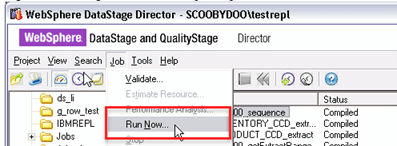
当您运行作业时,将执行以下活动:
- Capture程序读取SALES数据库日志中的六行更改,并将其插入CD表中。
- Apply程序从SALES的CD表中获取更改行,并将其插入STAGEDB的CCD表中。
- 两个DataStage提取作业从CCD表中拾取更改,并将它们写入productdataset.ds和inventory dataset.ds文件。
您可以通过查看数据集来检查上述步骤是否已执行。
第6步)按照以下步骤操作,
- 启动Designer。打开STAGEDB_ASN_PRODUCT_CCD_extract作业。
- 然后双击insert_into_a_dataset图标。在阶段编辑器中。单击View Data。
- 接受rows to be displayed窗口中的默认设置,然后单击OK。
数据集包含三个新行。检查更改是否已实现的最佳方法是滚动到Data Browser的最右侧。现在查看最后三行(见下图)。
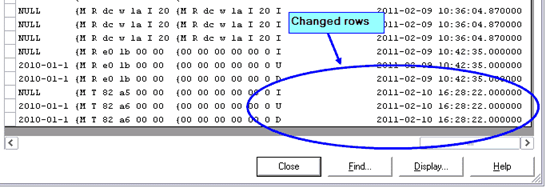
字母I、U和D分别表示INSERT、UPDATE和DELETE操作,这些操作导致了每一行的新行。
您可以对Inventory表执行相同的检查。
摘要
- Datastage是一款ETL工具,它从源提取、转换和加载数据到目标。
- 它通过提供高质量的数据来促进业务分析,以帮助获得业务智能。
- DataStage分为两部分:共享组件和运行时架构。
- DataStage有四个主要组件:
- 管理员
- 客户
- 设计器
- 总监
- 以下是IBM InfoSphere DataStage的关键方面:
- 数据转换
- 作业
- 并行处理
- 在作业设计中涉及的阶段有:
- 转换阶段
- 过滤器阶段
- 聚合器阶段
- 删除重复项阶段
- 连接阶段
- 查找阶段