什么是数据湖?它的架构:数据湖教程
什么是数据湖?
数据湖是一个存储库,可以存储大量结构化、半结构化和非结构化数据。它是一个以原始格式存储所有类型数据的地方,对账户大小或文件没有固定限制。它提供高数据量以提高分析性能和原生集成。
数据湖就像一个大型容器,与真实的湖泊和河流非常相似。就像湖泊有多个支流汇入一样,数据湖有结构化数据、非结构化数据、机器到机器的数据以及实时流动的日志。
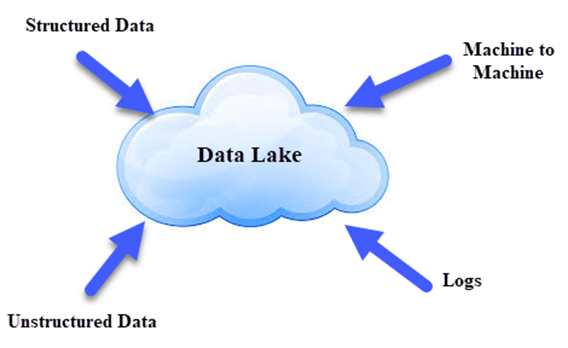
数据湖使数据民主化,是一种经济高效的方式来存储组织的所有数据以供后续处理。研究分析师可以专注于在数据中寻找有意义的模式,而不是数据本身。
与数据存储在文件和文件夹中的分层数据仓库不同,数据湖采用扁平架构。数据湖中的每个数据元素都被赋予一个唯一的标识符,并带有一组元数据信息。
为什么选择数据湖?
构建数据湖的主要目标是向数据科学家提供数据的原始视图。
使用数据湖的原因是
- 随着Hadoop等存储引擎的出现,存储不同信息变得容易。使用数据湖,无需将数据建模成企业范围的模式。
- 随着数据量、数据质量和元数据的增加,分析的质量也会提高。
- 数据湖提供业务敏捷性
- 机器学习和人工智能可用于进行有利可图的预测。
- 它为实施组织提供竞争优势。
- 没有数据孤岛结构。数据湖提供客户的360度视图,使分析更加强大。
数据湖架构
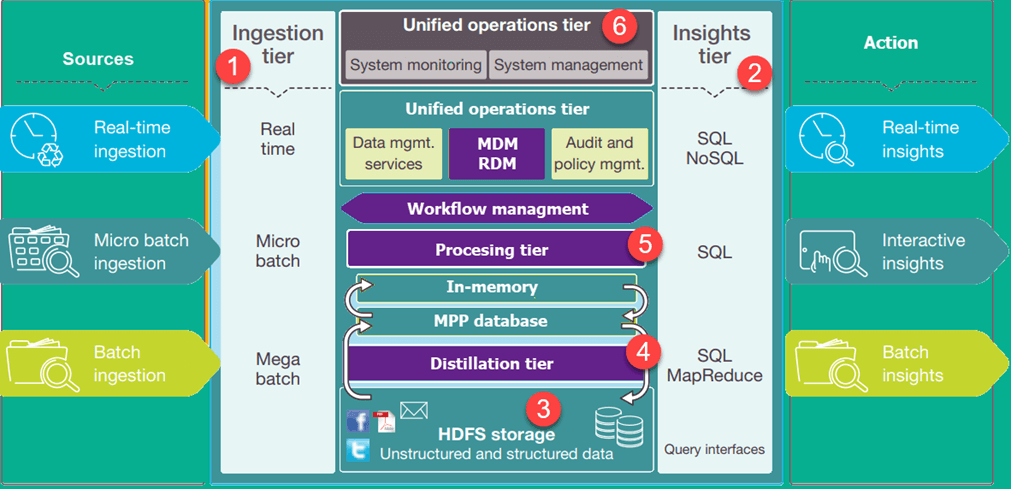
该图显示了业务数据湖的架构。下层代表大部分处于静止状态的数据,而上层则显示实时事务数据。这些数据以极低的延迟或无延迟地流经系统。以下是数据湖架构中的重要层:
- 摄取层:左侧的层表示数据源。数据可以批量或实时加载到数据湖中
- 洞察层:右侧的层表示研究端,用于使用系统中的洞察。SQL、NoSQL 查询甚至 Excel 都可用于数据分析。
- HDFS 是结构化和非结构化数据的一种经济高效的解决方案。它是系统中所有静止数据的着陆区。
- 提炼层从存储层获取数据并将其转换为结构化数据以进行更轻松的分析。
- 处理层运行分析算法和用户查询,具有不同的实时、交互式、批处理模式,以生成结构化数据以进行更轻松的分析。
- 统一操作层管理系统管理和监控。它包括审计和熟练度管理、数据管理、工作流管理。
数据湖的关键概念
以下是理解数据湖架构需要掌握的关键数据湖概念:
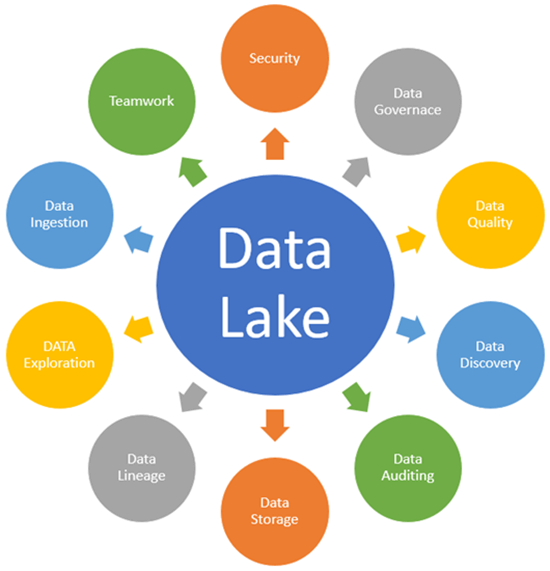
数据摄取
数据摄取允许连接器从不同的数据源获取数据并加载到数据湖中。
数据摄取支持
- 所有类型的结构化、半结构化和非结构化数据。
- 多种摄取方式,如批量、实时、一次性加载。
- 多种数据源,如数据库、Web 服务器、电子邮件、物联网和 FTP。
数据存储
数据存储应具有可伸缩性,提供经济高效的存储并允许快速访问数据探索。它应支持各种数据格式。
数据治理
数据治理是管理组织中使用的数据的可用性、可用性、安全性和完整性的过程。
安全性
安全需要在数据湖的每一层实施。它从存储、发现和消费开始。基本需求是阻止未经授权用户的访问。它应该支持不同的工具,以便通过易于导航的 GUI 和仪表板访问数据。
身份验证、核算、授权和数据保护是数据湖安全的一些重要功能。
数据质量
数据质量是数据湖架构的重要组成部分。数据用于获取商业价值。从低质量数据中提取洞察将导致低质量洞察。
数据发现
数据发现是在开始准备数据或分析之前的另一个重要阶段。在此阶段,使用标记技术来表达对数据的理解,通过组织和解释摄取到数据湖中的数据。
数据审计
两个主要的数据审计任务是跟踪关键数据集的变化。
- 跟踪重要数据集元素的变化
- 捕获这些元素如何/何时/由谁更改。
数据审计有助于评估风险和合规性。
数据沿袭
此组件处理数据的来源。它主要处理数据随时间移动的位置以及发生的情况。它简化了从源到目标的数据分析过程中的错误更正。
数据探索
这是数据分析的初始阶段。在开始数据探索之前,识别正确的数据集至关重要。
所有给定组件都需要协同工作,以便在数据湖构建中发挥重要作用,轻松演进和探索环境。
数据湖的成熟阶段
数据湖成熟阶段的定义因教科书而异。尽管核心内容保持不变。以下成熟阶段定义是从一个普通人的角度出发的。

阶段1:大规模处理和摄取数据
数据成熟度的第一阶段涉及提高数据转换和分析的能力。在此阶段,业务所有者需要根据其技能组合找到工具,以获取更多数据并构建分析应用程序。
阶段2:建立分析能力
这是第二阶段,涉及提高数据转换和分析的能力。在此阶段,公司使用最适合其技能组合的工具。他们开始获取更多数据并构建应用程序。在这里,企业数据仓库和数据湖的能力被结合使用。
第三阶段:EDW和数据湖协同工作
此步骤涉及将数据和分析尽可能多地交付给更多人。在此阶段,数据湖和企业数据仓库开始协同工作。两者都在分析中发挥作用
第四阶段:湖中的企业能力
在这个数据湖的成熟阶段,企业能力被添加到数据湖中。信息治理、信息生命周期管理能力和元数据管理被采纳。然而,很少有组织能达到这种成熟度,但未来这个数字将会增加。
数据湖实施的最佳实践
- 架构组件、它们的交互和已识别的产品应支持原生数据类型
- 数据湖的设计应由现有资源而非所需资源驱动。模式和数据需求在查询之前不会定义
- 设计应以与服务 API 集成的一次性组件为指导。
- 数据发现、摄取、存储、管理、质量、转换和可视化应独立管理。
- 数据湖架构应根据特定行业量身定制。它应确保该领域所需的功能是设计固有的部分
- 更快地引入新发现的数据源很重要
- 数据湖有助于定制管理以提取最大价值
- 数据湖应支持现有的企业数据管理技术和方法
构建数据湖的挑战
- 在数据湖中,数据量更大,因此流程必须更加依赖程序化管理
- 处理稀疏、不完整、易变的数据很困难
- 数据集和来源范围更广需要更大的数据治理和支持
数据湖和数据仓库的区别
| 参数 | 数据湖 | 数据仓库 |
|---|---|---|
| 数据 | 数据湖存储一切。 | 数据仓库只关注业务流程。 |
| 处理 | 数据主要未经处理 | 高度处理的数据。 |
| 数据类型 | 它可以是非结构化、半结构化和结构化的。 | 它主要是表格形式和结构。 |
| 任务 | 共享数据管理权 | 针对数据检索进行了优化 |
| 敏捷性 | 高度敏捷,可根据需要配置和重新配置。 | 与数据湖相比,它的敏捷性较低,并且配置固定。 |
| 用户 | 数据湖主要由数据科学家使用 | 业务专业人员广泛使用数据仓库 |
| 存储空间 | 数据湖设计用于低成本存储。 | 使用昂贵的存储以提供快速响应时间 |
| 安全性 | 提供较少的控制。 | 允许更好地控制数据。 |
| EDW的替代品 | 数据湖可以作为EDW的来源 | EDW的补充(而非替代) |
| 模式 | 读取时模式(无预定义模式) | 写入时模式(预定义模式) |
| 数据处理 | 有助于快速摄取新数据。 | 引入新内容耗时。 |
| 数据粒度 | 低细节或粒度的数据。 | 汇总或聚合级别的数据。 |
| 工具 | 可以使用Hadoop/Map Reduce等开源/工具 | 主要使用商业工具。 |
使用数据湖的收益和风险
以下是使用数据湖的一些主要好处
- 全面支持产品离子化和高级分析
- 提供经济高效的可扩展性和灵活性
- 从无限数据类型中创造价值
- 降低长期拥有成本
- 允许经济存储文件
- 快速适应变化
- 数据湖的主要优势在于不同内容源的集中化
- 来自不同部门的用户可能遍布全球,可以灵活访问数据
使用数据湖的风险
- 一段时间后,数据湖可能会失去相关性和发展势头
- 设计数据湖时存在较大的风险
- 非结构化数据可能导致无管理的混乱、不可用的数据、分散而复杂的工具、企业范围的协作、统一、一致和通用
- 它还增加了存储和计算成本
- 无法从其他使用过数据的人那里获得见解,因为没有关于以前分析师发现的沿袭记录
- 数据湖最大的风险是安全和访问控制。有时数据可以在没有任何监督的情况下放入数据湖中,因为有些数据可能涉及隐私和监管需求
摘要
- 数据湖是一个存储库,可以存储大量结构化、半结构化和非结构化数据。
- 构建数据湖的主要目标是向数据科学家提供数据的原始视图。
- 统一操作层、处理层、精炼层和HDFS是数据湖架构的重要层。
- 数据摄取、数据存储、数据质量、数据审计、数据探索、数据发现是数据湖架构的一些重要组成部分。
- 数据湖的设计应由现有资源而非所需资源驱动。
- 数据湖降低了长期拥有成本,并允许经济地存储文件。
- 数据湖最大的风险是安全和访问控制。有时数据可以在没有任何监督的情况下放入数据湖中,因为有些数据可能涉及隐私和监管需求。