2025年60+数据工程师面试问题与答案
面向初学者的数据工程师面试题
1) 解释数据工程。
数据工程是大数据中的一个术语。它侧重于数据收集和研究的应用。来自各种来源的数据只是原始数据。数据工程有助于将这些原始数据转化为有用的信息。
2) 什么是数据建模?
数据建模是一种将复杂软件设计记录为图表的方法,以便任何人都能轻松理解。它是数据对象与其之间的关系以及规则的概念化表示。

3) 列出数据建模中各种设计模式。
数据建模主要有两种模式:1)星型模式和2)雪花型模式。
4) 区分结构化数据和非结构化数据
以下是结构化数据和非结构化数据之间的区别
| 参数 | 结构化数据 | 非结构化数据 |
|---|---|---|
| 存储空间 | DBMS | 未管理的文件结构 |
| 标准 | ADO.net、ODBC和SQL | STMP、XML、CSV和SMS |
| 集成工具 | ELT(提取、加载、转换) | 手动数据录入或批处理(包括代码) |
| 扩展性 | 模式扩展性困难 | 扩展性非常容易。 |
5) 解释 Hadoop 应用程序的所有组件
以下是 Hadoop 应用程序的组件
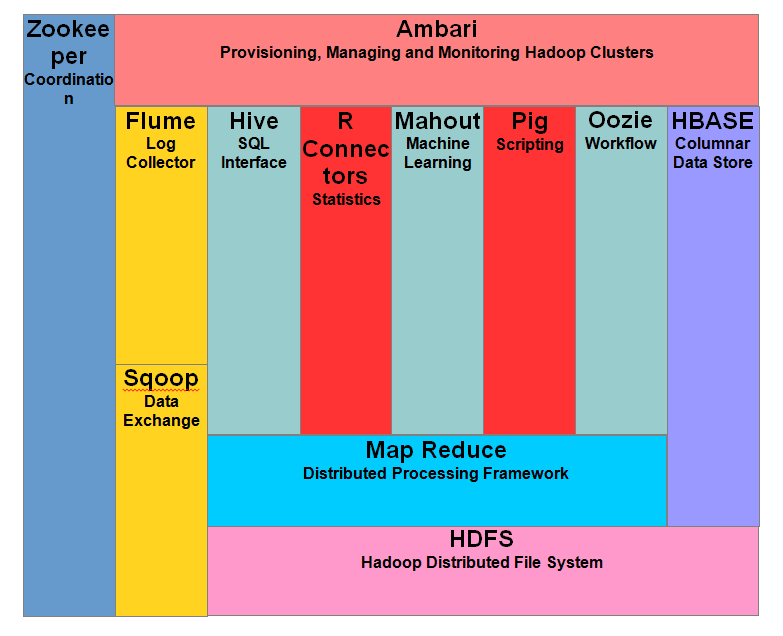
- Hadoop Common:这是一组 Hadoop 使用的通用实用程序和库。
- HDFS:此 Hadoop 应用程序与 Hadoop 数据存储的文件系统相关。它是一个具有高带宽的分布式文件系统。
- Hadoop MapReduce:它基于算法,用于提供大规模数据处理。
- Hadoop YARN:它用于 Hadoop 群集内的资源管理。它还可以用于用户的任务调度。
6) 什么是 NameNode?
它是 HDFS 的中心。它存储 HDFS 的数据并跟踪群集中的各种文件。实际数据不存储在这里。数据存储在 DataNodes 中。
7) 定义 Hadoop Streaming
它是一个实用程序,允许创建 Map 和 Reduce 作业并将它们提交到特定的群集。
8) HDFS 的全称是什么?
HDFS 代表 Hadoop 分布式文件系统 (Hadoop Distributed File System)。
9) 定义 HDFS 中的块 (Block) 和块扫描器 (Block Scanner)
块是数据文件的最小单元。Hadoop 会自动将大文件分割成小块。
块扫描器会验证 DataNode 上存在的块列表。
10) 当块扫描器检测到损坏的数据块时会发生什么步骤?
以下是当块扫描器发现损坏的数据块时发生的步骤
1) 首先,当块扫描器发现损坏的数据块时,DataNode 会向 NameNode 报告
2) NameNode 使用损坏块的副本开始创建新副本的过程。
3) 正确副本的复制计数会尝试与复制因子匹配。如果找到匹配项,损坏的数据块将不会被删除。
11) 说出 NameNode 从 DataNode 收到的两个消息?
NameNode 从 DataNode 收到的消息有两个。它们是 1) 块报告 (Block report) 和 2) 心跳 (Heartbeat)。
12) 列出 Hadoop 中各种 XML 配置文件?
Hadoop 中有五个 XML 配置文件
- Mapred-site
- Core-site
- HDFS-site
- Yarn-site
13) 大数据有哪些“4V”?
大数据的“4V”是
- 速度
- 多样性 (Variety)
- 体量 (Volume)
- 真实性 (Veracity)
14) 解释 Hadoop 的特性
Hadoop 的重要特性是
- 它是一个开源框架,免费可用。
- Hadoop 与多种硬件兼容,并且易于在特定节点内访问新硬件。
- Hadoop 支持更快速的分布式数据处理。
- 它将数据存储在与其余操作无关的群集中。
- Hadoop 允许为每个块创建 3 个副本,分布在不同的节点上。
15) 解释 Reduce 函数的主要方法
- setup(): 用于配置输入数据大小和分布式缓存等参数。
- cleanup(): 此方法用于清理临时文件。
- reduce(): 它是 reduce 的核心,每当遇到一个键时,就会被调用一次,并进行相应的约简任务。
16) COSHH 的缩写是什么?
COSHH 的缩写是 Classification and Optimization based Schedule for Heterogeneous Hadoop systems (异构 Hadoop 系统的基于分类和优化的调度)。
17) 解释星型模式
星型模式或星型连接模式是最简单的数据仓库模式。它被称为星型模式是因为其结构像一颗星。在星型模式中,星的中心可以有一个事实表和多个相关的维度表。此模式用于查询大量数据集。
18) 如何部署大数据解决方案?
要部署大数据解决方案,请遵循以下步骤。
1) 使用 RDBMS、SAP、MySQL、Salesforce 等数据源集成数据
2) 将提取的数据存储在 NoSQL 数据库或 HDFS 中。
3) 使用 Pig、Spark 和 MapReduce 等处理框架部署大数据解决方案。
19) 解释 FSCK
文件系统检查 (File System Check) 或 FSCK 是 HDFS 使用的命令。FSCK 命令用于检查文件中的不一致和问题。
20) 解释雪花型模式
雪花型模式是星型模式的扩展,并添加了额外的维度。之所以称为雪花型,是因为其图表看起来像雪花。维度表被规范化,将数据拆分到更多的表中。
21) 区分星型模式和雪花型模式
| 星型 | 雪花型模式 |
| 维度层次结构存储在维度表中。 | 每个层次结构都存储在单独的表中。 |
| 数据冗余的可能性很高 | 数据冗余的可能性很低。 |
| 它拥有非常简单的数据库设计 | 它拥有复杂的数据库设计 |
| 为立方体处理提供更快的途径 | 由于复杂的连接,立方体处理速度很慢。 |
22) 解释 Hadoop 分布式文件系统
Hadoop 使用 S3、HFTP FS、FS 和 HDFS 等可扩展的分布式文件系统。Hadoop 分布式文件系统是基于 Google 文件系统构建的。这种文件系统设计得易于在大型计算机群集上运行。
23) 解释数据工程师的主要职责
数据工程师有许多职责。他们管理数据源系统。数据工程师简化复杂的数据结构并防止数据重复。很多时候他们还提供 ELT 和数据转换。
24) YARN 的全称是什么?
YARN 的全称是 Yet Another Resource Negotiator (又一个资源协调器)。
25) 列出 Hadoop 中的各种模式
Hadoop 的模式有 1) 独立模式 (Standalone mode) 2) 伪分布式模式 (Pseudo distributed mode) 3) 完全分布式模式 (Fully distributed mode)。
26) 如何在 Hadoop 中实现安全性?
执行以下步骤以在 Hadoop 中实现安全性
1) 第一步是保护客户端到服务器的认证通道。为客户端提供时间戳。
2) 第二步,客户端使用收到的时间戳向 TGS 请求服务票证。
3) 最后一步,客户端使用服务票证进行自我认证到特定服务器。
27) Hadoop 中的心跳 (Heartbeat) 是什么?
在 Hadoop 中,NameNode 和 DataNode 相互通信。心跳是 DataNode 定期发送给 NameNode 的信号,以表明其存在。
28) 区分 Hadoop 中的 NAS 和 DAS
| NAS | DAS |
| 存储容量为 10^9 到 10^12 字节。 | 存储容量为 10^9 字节。 |
| 每 GB 管理成本适中。 | 每 GB 管理成本高。 |
| 通过以太网或 TCP/IP 传输数据。 | 通过 IDE/SCSI 传输数据 |
29) 列出数据工程师使用的重要领域或语言
以下是数据工程师使用的一些领域或语言
- 概率和线性代数
- 机器学习
- 趋势分析和回归
- Hive QL 和 SQL 数据库
30) 什么是大数据?
它是大量结构化和非结构化数据,传统数据存储方法难以轻松处理。数据工程师使用 Hadoop 来管理大数据。
面向有经验者的数据工程师面试题
31) 什么是 FIFO 调度?
它是 Hadoop 作业调度算法。在此 FIFO 调度中,报告程序从工作队列中选择作业,最先选择最旧的作业。
32) Mention default port numbers on which task tracker, NameNode, and job tracker run in Hadoop
Hadoop 中任务跟踪器 (task tracker)、NameNode 和作业跟踪器 (job tracker) 运行的默认端口号如下
- 任务跟踪器运行在 50060 端口
- NameNode 运行在 50070 端口
- 作业跟踪器运行在 50030 端口
33) 如何禁用 HDFS Data Node 上的块扫描器?
为了禁用 HDFS Data Node 上的块扫描器,将 dfs.datanode.scan.period.hours 设置为 0。
34) 如何定义 Hadoop 中两个节点之间的距离?
距离等于到最近节点的距离之和。getDistance() 方法用于计算两个节点之间的距离。
35) 为什么要在 Hadoop 中使用商用硬件?
商用硬件易于获取且价格合理。它是一个与 Windows、MS-DOS 或 Linux 兼容的系统。
36) 定义 HDFS 中的复制因子 (replication factor)
复制因子是系统中文件的总副本数。
37) NameNode 中存储了什么数据?
NameNode 存储 HDFS 的元数据,如块信息和命名空间信息。
38) 什么是机架感知 (Rack Awareness)?
在 Hadoop 群集中,NameNode 利用 DataNode 来改善网络流量,同时读取或写入更靠近附近机架的任何文件。NameNode 维护每个 DataNode 的机架 ID 以获取机架信息。这个概念被称为 Hadoop 中的机架感知。
39) Secondary NameNode 的功能是什么?
以下是 Secondary NameNode 的功能
- FsImage,它存储 EditLog 和 FsImage 文件的副本。
- NameNode 崩溃:如果 NameNode 崩溃,则可以使用 Secondary NameNode 的 FsImage 来重新创建 NameNode。
- 检查点 (Checkpoint):Secondary NameNode 使用它来确认 HDFS 中的数据没有损坏。
- 更新 (Update):它会自动更新 EditLog 和 FsImage 文件。它有助于保持 Secondary NameNode 上的 FsImage 文件是最新的。
40) 当 NameNode 宕机,用户提交新作业时会发生什么?
NameNode 是 Hadoop 中的单点故障,因此用户无法提交新作业。如果 NameNode 宕机,作业可能会失败,因此用户需要等待 NameNode 重启才能运行任何作业。
41) Hadoop 中 Reducer 的基本阶段是什么?
Reducer 在 Hadoop 中有三个基本阶段
1. Shuffle:在这里,Reducer 复制 Mapper 的输出。
2. Sort:在排序中,Hadoop 使用相同的键对 Reduce 的输入进行排序。
3. Reduce:在此阶段,将与键关联的值进行约简,以将数据合并到最终输出。
42) 为什么 Hadoop 使用 Context 对象?
Hadoop 框架使用 Context 对象与 Mapper 类一起与剩余系统进行交互。Context 对象在其构造函数中获取系统配置详细信息和作业。
我们在 setup()、cleanup() 和 map() 方法中使用 Context 对象来传递信息。此对象在 Map 操作期间提供关键信息。
43) 定义 Hadoop 中的 Combiner
它是 Map 和 Reduce 之间的一个可选步骤。Combiner 接收 Map 函数的输出,创建键值对,并提交给 Hadoop Reducer。Combiner 的任务是将 Map 的最终结果汇总成具有相同键的汇总记录。
44) HDFS 中可用的默认复制因子是多少?它表示什么?
HDFS 中可用的默认复制因子是三个。默认复制因子表示每个数据将有三个副本。
45) 你明白 Hadoop 中的数据局部性 (Data Locality) 吗?
在大数据系统中,数据量巨大,因此在网络上传输数据没有意义。现在,Hadoop 试图将计算移近数据。这样,数据就保留在本地存储位置。
46) 定义 HDFS 中的 Balancer
在 HDFS 中,Balancer 是管理员使用的管理工具,用于重新平衡 DataNodes 之间的数据,并将块从过度使用的节点移动到使用不足的节点。
47) 解释 HDFS 中的安全模式 (Safe mode)
它是群集中 NameNode 的只读模式。最初,NameNode 处于安全模式。它会阻止在安全模式下写入文件系统。此时,它会从所有 DataNodes 收集数据和统计信息。
48) Apache Hadoop 中分布式缓存的重要性是什么?
Hadoop 有一个有用的实用程序,称为分布式缓存,它通过缓存应用程序使用的文件来提高作业性能。应用程序可以使用 JobConf 配置指定要缓存的文件。
Hadoop 框架会提前将这些文件的副本复制到将要执行任务的节点上。这是在任务执行开始之前完成的。分布式缓存支持只读文件以及 zip 和 jar 文件的分发。
49) Hive 中的 Metastore 是什么?
它存储模式以及 Hive 表的位置。
Hive 表定义、映射和元数据存储在 Metastore 中。这可以存储在 JPOX 支持的 RDBMS 中。
50) 你如何理解 Hive 中的 SerDe?
SerDe 是序列化器 (Serializer) 或反序列化器 (Deserializer) 的简称。在 Hive 中,SerDe 允许以任何你想要的格式从表中读取数据并写入特定字段。
51) 列出 Hive 数据模型中可用的组件
Hive 数据模型包含以下组件
- 表
- 分区 (Partitions)
- 分桶 (Buckets)
52) 解释 Hive 在 Hadoop 生态系统中的用途。
Hive 提供了一个接口来管理存储在 Hadoop 生态系统中的数据。Hive 用于映射和处理 HBase 表。Hive 查询被转换为 MapReduce 作业,以隐藏创建和运行 MapReduce 作业相关的复杂性。
53) 列出 Hive 支持的各种复杂数据类型/集合
Hive 支持以下复杂数据类型
- Map
- Struct
- 数组
- 联合
54) 解释 Hive 中 .hiverc 文件的使用方式?
在 Hive 中,.hiverc 是初始化文件。当我们启动 Hive 的命令行界面 (CLI) 时,该文件会被加载。我们可以在 .hiverc 文件中设置参数的初始值。
55) Hive 是否可以为单个数据文件创建多个表?
是的,我们可以为一个数据文件创建多个表模式。Hive 将模式保存在 Hive Metastore 中。基于此模式,我们可以从相同的数据中检索不同的结果。
56) 解释 Hive 中提供的不同 SerDe 实现
Hive 中有许多 SerDe 实现。你也可以编写自己的自定义 SerDe 实现。以下是一些著名的 SerDe 实现
- OpenCSVSerde
- RegexSerDe
- DelimitedJSONSerDe
- ByteStreamTypedSerDe
57) 列出 Hive 中提供的表生成函数
以下是表生成函数列表
- Explode(array)
- JSON_tuple()
- Stack()
- Explode(map)
58) Hive 中的倾斜表 (Skewed table) 是什么?
倾斜表是指包含大量重复列值的表。在 Hive 中,当我们在创建时将表指定为 SKEWED,则倾斜值会被写入单独的文件,而其余值则进入另一个文件。
59) 列出 MySQL 中 create 语句创建的对象。
MySQL 中 create 语句创建的对象如下
- 数据库
- 索引
- 表
- 用户
- 过程
- 触发器
- Event
- 查看
- 函数
60) 如何查看 MySQL 中的数据库结构?
为了查看 MySQL 中的数据库结构,你可以使用
DESCRIBE 命令。此命令的语法是 DESCRIBE Table name;。
面向数据工程师的SQL面试题
61) 如何在 MySQL 表列中搜索特定字符串?
使用正则表达式运算符在 MySQL 列中搜索字符串。在这里,我们还可以定义各种类型的正则表达式并使用正则表达式进行搜索。
62) 解释数据分析和大数据如何增加公司收入?
以下是数据分析和大数据增加公司收入的方法
- 高效利用数据以确保业务增长。
- 提高客户价值。
- 将分析转化为改进人员配置水平的预测。
- 降低组织的生产成本。
这些面试问题也将有助于您的口试