监督式学习 vs 无监督式学习:它们之间的区别
监督学习与无监督学习的关键区别
- 在监督学习中,您使用“已标记”的数据来训练机器。
- 无监督学习是一种机器学习技术,您无需监督模型。
- 监督学习允许您从过去的经验中收集数据或产生数据输出。
- 无监督机器学习可帮助您在数据中发现各种未知模式。
- 回归和分类是两种监督机器学习技术。
- 聚类和关联是无监督学习的两种类型。
- 在监督学习模型中,将提供输入和输出变量,而在无监督学习模型中,仅提供输入数据。
什么是监督机器学习?
在监督学习中,您使用“已标记”的数据来训练机器。这意味着某些数据已标记有正确答案。这可以比作在有监督者或老师在场的情况下进行的学习。
监督学习算法从标记的训练数据中学习,可帮助您预测未预料到的数据的结果。成功构建、扩展和部署准确的监督机器学习数据科学模型需要一支技术精湛的数据科学团队花费时间和技术专业知识。此外,数据科学家必须重建模型,以确保提供的见解在数据发生变化之前保持真实。
什么是无监督学习?
无监督学习是一种机器学习技术,您无需监督模型。相反,您需要让模型自行工作以发现信息。它主要处理未标记的数据。
与监督学习相比,无监督学习算法允许您执行更复杂的处理任务。尽管如此,与其他自然学习的深度学习和强化学习方法相比,无监督学习可能更不可预测。
为什么选择监督学习?
- 监督学习允许您从过去的经验中收集数据或产生数据输出。
- 借助经验帮助您优化性能标准
- 监督机器学习可帮助您解决各种现实世界的计算问题。
为什么选择无监督学习?
以下是使用无监督学习的主要原因
- 无监督机器学习可在数据中发现各种未知模式。
- 无监督方法可帮助您找到可用于分类的特征。
- 它实时发生,因此所有要分析的数据都要在学习者面前进行标记。
- 从计算机获取未标记数据比获取需要手动干预的标记数据更容易。
监督学习如何工作?
例如,您想训练一台机器来帮助您预测从工作地点开车回家需要多长时间。在这里,您首先创建一个已标记的数据集。此数据包括
- 天气状况
- 一天中的时间
- 节假日
所有这些细节都是您的输入。输出是那天开车回家所需的时间。

您凭直觉就知道,如果外面下雨,开车回家会花费更长的时间。但机器需要数据和统计信息。
现在让我们看看如何开发一个监督学习模型来帮助用户确定通勤时间。您需要做的第一件事是创建一个训练数据集。此训练集将包含总通勤时间以及天气、时间等相应因素。基于此训练集,您的机器可能会发现降雨量与您回家所需时间之间存在直接关系。
因此,它会确定雨下得越大,您开车回家所需的时间就越长。它还可能看到您下班的时间与您在路上的时间之间的联系。
您越接近下午6点,回家所需的时间就越长。您的机器可能会从您的标记数据中找到一些关系。
这是您的数据模型启动的地方。它开始影响雨水如何影响人们的驾驶方式。它还开始注意到在一天中的特定时间有更多的人出行。
无监督学习如何工作?
我们以一个婴儿和她的家庭狗为例。

她认识并辨认出这只狗。几周后,一位家庭朋友带了一只狗来,并试图和婴儿玩耍。

婴儿以前没见过这只狗。但它识别出许多特征(2只耳朵、眼睛、四条腿行走)与她的宠物狗相似。她识别出一种像狗一样的新动物。这就是无监督学习,您没有被教导,而是从数据(在本例中是关于狗的数据)中学习。如果这是监督学习,这位家庭朋友就会告诉婴儿这是一只狗。
监督机器学习技术的类型
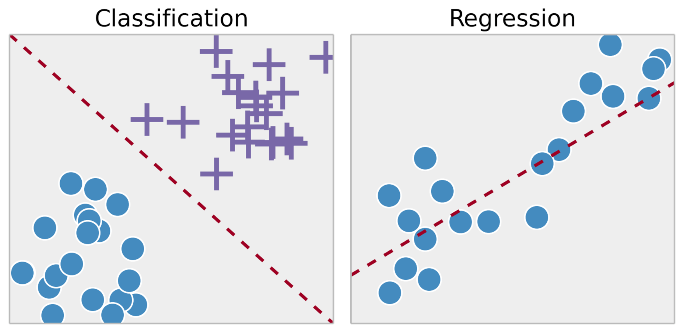
回归测试
回归技术使用训练数据预测单个输出值。
示例:您可以使用回归根据训练数据预测房价。输入变量将是地点、房屋大小等。
分类
分类是指将输出分组到类中。如果算法尝试将输入标记到两个不同的类别中,则称为二元分类。选择两个以上的类别称为多类别分类。
示例:确定某人是否会拖欠贷款。
优点:输出始终具有概率解释,并且可以对算法进行正则化以避免过拟合。
缺点:当存在多个或非线性决策边界时,逻辑回归的性能可能不佳。这种方法不够灵活,因此无法捕捉更复杂的关系。
无监督机器学习技术的类型
无监督学习问题进一步分为聚类和关联问题。
聚类

聚类是无监督学习中的一个重要概念。它主要处理在未分类的数据集合中查找结构或模式。聚类算法将处理您的数据,并在数据中存在自然集群(组)时找到它们。您还可以修改您的算法应识别的集群数量。它允许您调整这些组的粒度。
关联
关联规则允许您在大型数据库中建立数据对象之间的关联。这项无监督技术是关于发现大型数据库中变量之间的令人兴奋的关系的。例如,购买新房的人更有可能购买新家具。
其他示例
- 按基因表达测量分组的一组癌症患者
- 根据浏览和购买历史分组的购物者群
- 根据电影观众评分分组的电影
监督学习与无监督学习的区别

| 参数 | 监督机器学习技术 | 无监督机器学习技术 |
|---|---|---|
| 过程 | 在监督学习模型中,将提供输入和输出变量。 | 在无监督学习模型中,仅提供输入数据。 |
| 输入数据 | 算法使用有标签数据进行训练。 | 算法用于未标记的数据。 |
| 使用的算法 | 支持向量机、神经网络、线性回归和逻辑回归、随机森林以及分类树。 | 无监督算法可分为不同类别:如聚类算法、K-均值、层次聚类等。 |
| 计算复杂度 | 监督学习是一种更简单的方法。 | 无监督学习计算复杂。 |
| 数据使用 | 监督学习模型使用训练数据学习输入与输出之间的联系。 | 无监督学习不使用输出数据。 |
| 结果的准确性 | 高度准确且可靠的方法。 | 准确性和可靠性较低的方法。 |
| 实时学习 | 学习方法离线进行。 | 学习方法实时进行。 |
| 类别数量 | 已知类别数量。 | 未知类别数量。 |
| 主要缺点 | 在监督学习中,对大数据进行分类可能是一个真正的挑战。 | 您无法获得有关数据分类的精确信息,并且由于无监督学习中使用的数据是已标记且未知的,因此无法获得输出。 |