SQL Server 架构(详解)
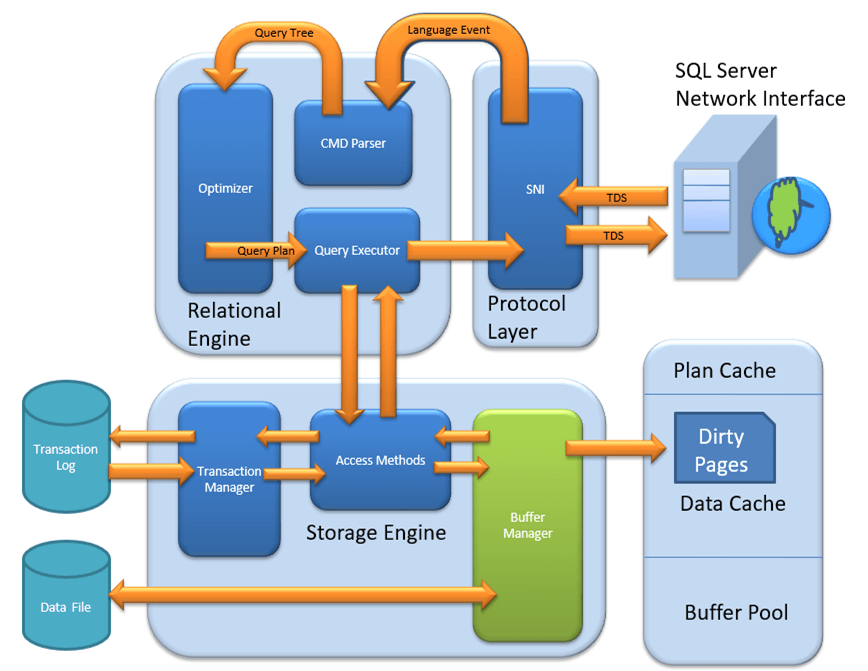
MS SQL Server 是一种客户端-服务器架构。MS SQL Server 进程以客户端应用程序发送请求开始。SQL Server 接受、处理请求并用处理过的数据响应请求。让我们详细讨论下图所示的整个架构
如下图所示,SQL Server 架构包含三个主要组件
- 协议层
- 关系引擎
- 存储引擎
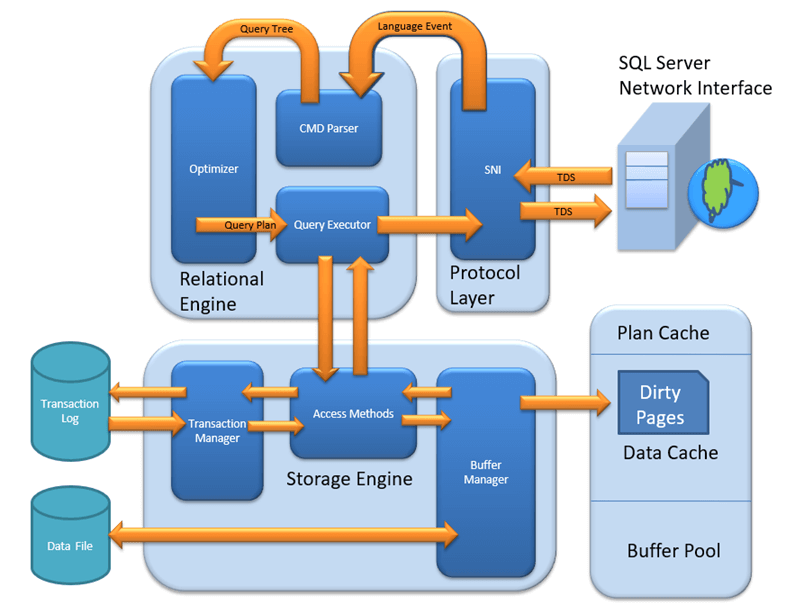
协议层 – SNI
MS SQL SERVER 协议层支持 3 种客户端服务器架构。我们将从 MS SQL Server 支持的“三种客户端服务器架构”开始。
共享内存
让我们回顾一下一个清晨的对话场景。
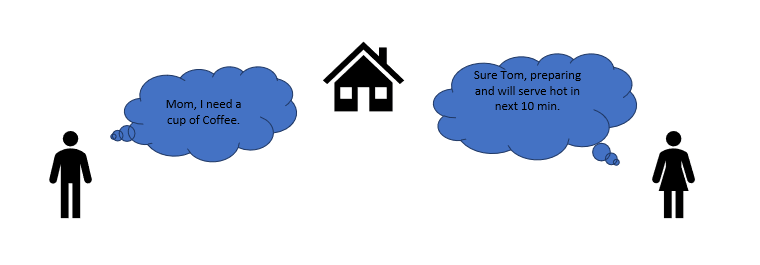
妈妈和汤姆 – 这里汤姆和他的妈妈在同一个逻辑位置,即在家里。汤姆可以点咖啡,妈妈也可以热腾腾地给他端上来。
MS SQL SERVER – 这里MS SQL服务器提供共享内存协议。这里的客户端和MS SQL服务器运行在同一台机器上。两者都可以通过共享内存协议进行通信。
类比:让我们将上述两个场景中的实体进行映射。我们可以轻松地将汤姆映射为客户端,妈妈映射为 SQL 服务器,家映射为机器,语言沟通映射为共享内存协议。
配置和安装说明
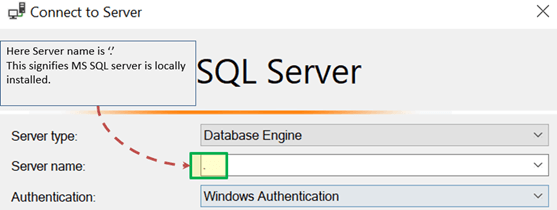
连接本地数据库 – 在SQL Management Studio中,“服务器名称”选项可以是
“.”
“localhost”
“127.0.0.1”
“Machine\Instance”
TCP/IP
现在考虑晚上,汤姆想出去玩。他想从一家知名的咖啡店订购咖啡。这家咖啡店离他家有 10 公里远。

这里汤姆和星巴克在不同的物理位置。汤姆在家,星巴克在繁忙的市场。他们通过蜂窝网络进行通信。同样,MS SQL SERVER 能够通过TCP/IP 协议进行交互,其中客户端和 MS SQL Server 彼此远程,并且安装在单独的机器上。
类比:让我们将上述两个场景中的实体进行映射。我们可以轻松地将汤姆映射为客户端,星巴克映射为 SQL 服务器,家/市场映射为远程位置,最后蜂窝网络映射为 TCP/IP 协议。
配置/安装说明
- 在 SQL Management Studio 中 – 通过 TCP\IP 连接时,“服务器名称”选项必须是“服务器的 Machine\Instance”。
- SQL Server 在 TCP/IP 中使用端口 1433。
命名管道
最后在晚上,汤姆想喝点清淡的绿茶,这是他的邻居 Sierra 泡得很好的。

这里汤姆和他的邻居Sierra 在同一个物理位置,彼此是邻居。他们通过内部网络进行通信。同样,MS SQL SERVER能够通过命名管道协议进行交互。这里的客户端和MS SQL SERVER通过LAN连接。
类比:让我们将上述两个场景中的实体进行映射。我们可以轻松地将汤姆映射为客户端,Sierra 映射为 SQL 服务器,邻居映射为 LAN,最后内部网络映射为命名管道协议。
配置/安装说明
- 通过命名管道进行连接。此选项默认禁用,需要通过 SQL 配置管理器启用。
什么是 TDS?
既然我们知道了有三种客户端-服务器架构,让我们来看看 TDS
- TDS 代表表格数据流(Tabular Data Stream)。
- 所有 3 种协议都使用 TDS 数据包。TDS 被封装在网络数据包中,以实现从客户端到服务器的数据传输。
- TDS 最初由 Sybase 开发,现在归 Microsoft 所有
关系引擎
关系引擎也称为查询处理器。它包含SQL Server组件,这些组件确定查询需要做什么以及如何最好地完成。它负责通过请求存储引擎的数据和处理返回的结果来执行用户查询。
正如架构图所示,关系引擎有3 个主要组件。让我们详细研究一下这些组件
CMD 解析器
从协议层接收到的数据然后传递给关系引擎。“CMD 解析器”是关系引擎接收查询数据的第一个组件。CMD 解析器的主要工作是检查查询的语法和语义错误。最后,它生成查询树。让我们详细讨论。
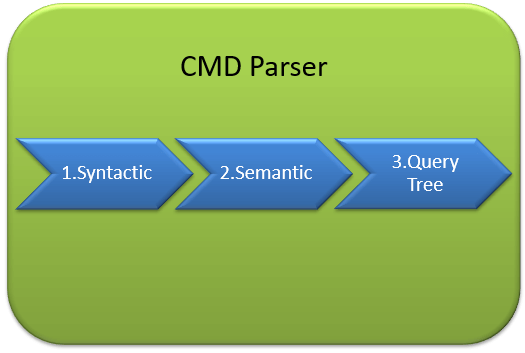
语法检查
- 与所有其他编程语言一样,MS SQL 也有预定义的关键字。此外,SQL Server 拥有自己的语法,SQL Server 可以理解。
- SELECT、INSERT、UPDATE 等属于 MS SQL 预定义关键字列表。
- CMD 解析器执行语法检查。如果用户输入不遵循这些语言的语法或语法规则,它将返回错误。
示例:假设一个俄罗斯人去了一家日本餐厅。他用俄语点餐。不幸的是,服务员只懂日语。最可能的结果是什么?
答案是——服务员无法进一步处理订单。
SQL Server 接受的语法或语言不应有任何偏差。如果有,SQL Server 无法处理,因此会返回错误消息。
我们将在接下来的教程中学习更多关于 MS SQL 查询的内容。但是,请参考下面最基本的查询语法
SELECT * from <TABLE_NAME>;
现在,为了理解语法的作用,假设用户运行了如下基本查询
SELECR * from <TABLE_NAME>
请注意,用户输入的是“SELECR”而不是“SELECT”。
结果:CMD 解析器将解析此语句并抛出错误消息。因为“SELECR”不遵循预定义的关键字名称和语法。这里 CMD 解析器期望的是“SELECT”。
语义检查
- 这是由标准化器执行的。
- 最简单的形式是,它检查查询中的列名、表名是否存在于模式中。如果存在,则将其绑定到查询。这也称为绑定。
- 当用户查询包含 VIEW 时,复杂性会增加。标准化器会替换为内部存储的视图定义等。
让我们通过以下示例来理解这一点——
SELECT * from USER_ID
结果:CMD 解析器将为此语句进行语义检查。解析器将抛出错误消息,因为标准化器找不到请求的表(USER_ID),因为它不存在。
创建查询树
- 此步骤生成查询可以运行的不同执行树。
- 请注意,所有不同的树都具有相同的预期输出。
优化器
优化器的作用是为用户查询创建执行计划。这是将决定用户查询将如何执行的计划。
请注意,并非所有查询都经过优化。优化是针对 DML(数据修改语言)命令(如 SELECT、INSERT、DELETE 和 UPDATE)进行的。这些查询首先被标记,然后发送到优化器。DDL 命令(如 CREATE 和 ALTER)不进行优化,而是被编译成内部形式。查询成本根据 CPU 使用率、内存使用率和输入/输出需求等因素计算。
优化器的作用是找到最便宜的、不是最好的、成本效益最高的执行计划。
在我们深入研究优化器的技术细节之前,请考虑以下现实生活示例
示例
假设您想开设一个在线银行账户。您已经知道有一家银行最多需要 2 天来开设账户。但是,您还有另外 20 家银行的列表,它们可能需要不到 2 天的时间,也可能不需要。您可以开始与这些银行联系,以确定哪些银行需要不到 2 天的时间。现在,您可能找不到一家需要不到 2 天的银行,而且搜索活动本身还会额外花费时间。最好是立即在第一家银行开设账户。
结论:明智地选择很重要。确切地说,选择最佳选项,而不是最便宜的选项。
同样,MSSQL 优化器在内置的穷举/启发式算法上运行。目标是最大限度地减少查询运行时间。所有优化器算法都是Microsoft 的专有且保密的。尽管如此,以下是 MS SQL 优化器执行的高级步骤。优化搜索遵循下图所示的三个阶段
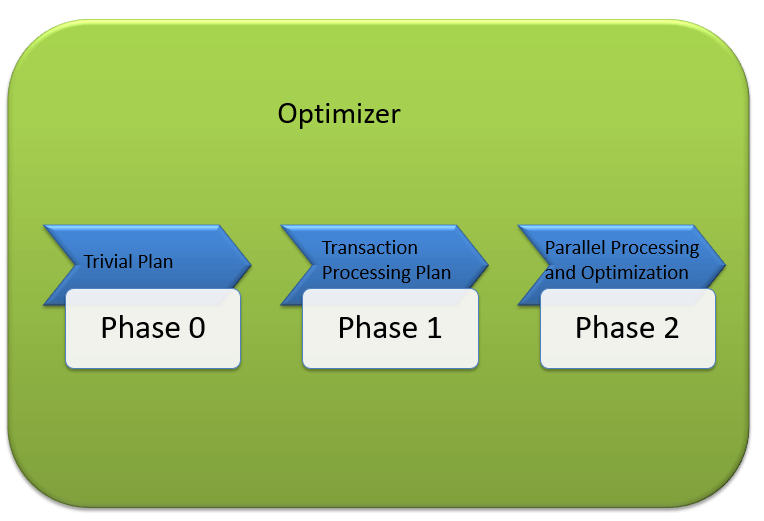
阶段 0:搜索平凡计划
- 这也被称为预优化阶段。
- 在某些情况下,可能只有一个实际可行、可用的计划,称为平凡计划。无需创建优化计划。原因是,搜索更多只会找到相同的运行时间执行计划。而且还需要额外花费搜索优化计划的成本,这根本是不需要的。
- 如果未找到平凡计划,则开始第一个阶段。
阶段 1:搜索事务处理计划
- 这包括搜索简单和复杂计划。
- 简单计划搜索:查询涉及的列和索引的历史数据将用于统计分析。这通常包括但不限于每个表一个索引。
- 如果仍然找不到简单计划,则会搜索更复杂的计划。它涉及每个表多个索引。
阶段 2:并行处理和优化。
- 如果以上策略均无效,优化器将搜索并行处理的可能性。这取决于机器的处理能力和配置。
- 如果仍然无法实现,则开始最终优化阶段。现在,最终优化的目标是找到执行查询的最佳所有其他可能性。最终优化阶段的算法是 Microsoft 的专有算法。
查询执行器
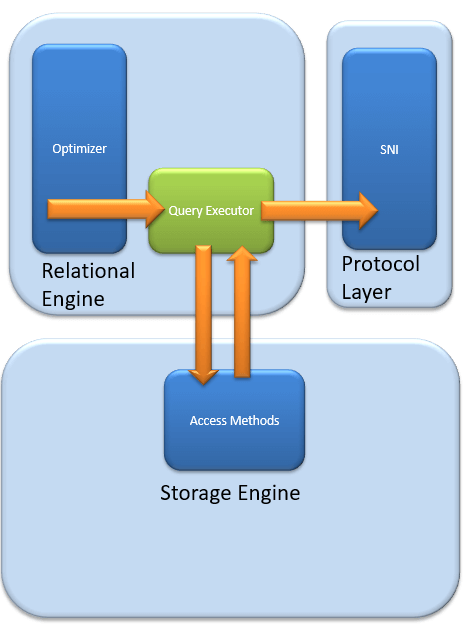
查询执行器调用访问方法。它提供执行所需数据获取逻辑的执行计划。一旦从存储引擎获取到数据,结果就会发布到协议层。最后,数据发送给最终用户。
存储引擎
存储引擎的作用是将数据存储在磁盘或 SAN 等存储系统中,并在需要时检索数据。在深入研究存储引擎之前,让我们先了解一下数据库中数据的存储方式以及可用的文件类型。
数据文件和扩展区
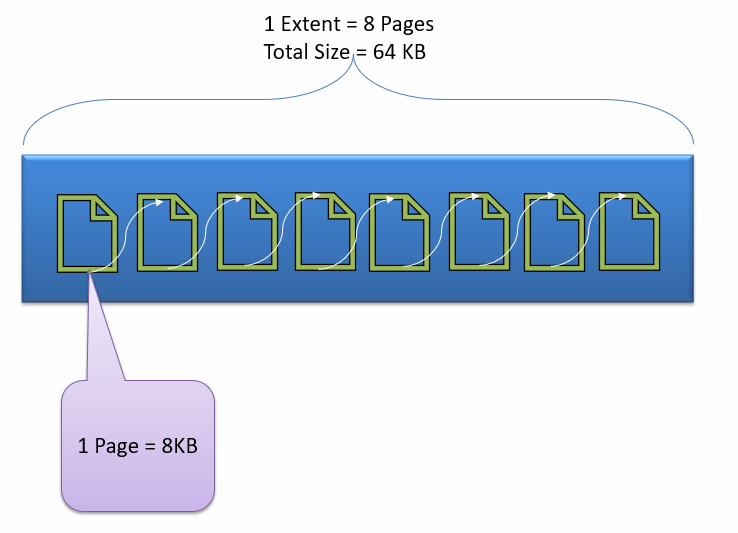
数据文件以数据页的形式物理存储数据,每个数据页的大小为 8KB,是 SQL Server 中最小的存储单元。这些数据页在逻辑上组合成扩展区。在 SQL Server 中,没有对象被分配页面。
对象的维护通过扩展区完成。页面包含一个称为页面头的部分,大小为 96 字节,包含关于页面(如页面类型、页面编号、已用空间大小、可用空间大小以及指向下一个页面和上一个页面的指针等)的元数据信息。
文件类型
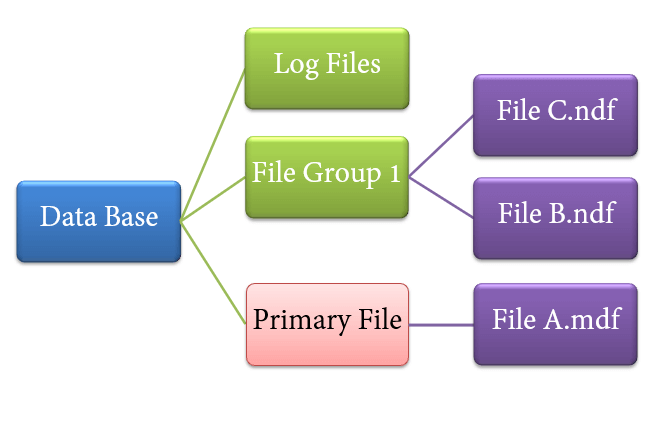
- 主文件
- 每个数据库包含一个主文件。
- 此文件存储与表、视图、触发器等相关的所有重要数据。
- 扩展名通常是 .mdf,但可以是任何扩展名。
- 辅助文件
- 数据库可能包含零个或多个辅助文件。
- 这是可选的,包含用户特定数据。
- 扩展名通常是 .ndf,但可以是任何扩展名。
- 日志文件
- 也称为写前日志(Write ahead logs)。
- 扩展名是 .ldf
- 用于事务管理。
- 这用于从任何不需要的实例中恢复。执行回滚未提交事务的重要任务。
存储引擎有 3 个组件;让我们详细看看它们。
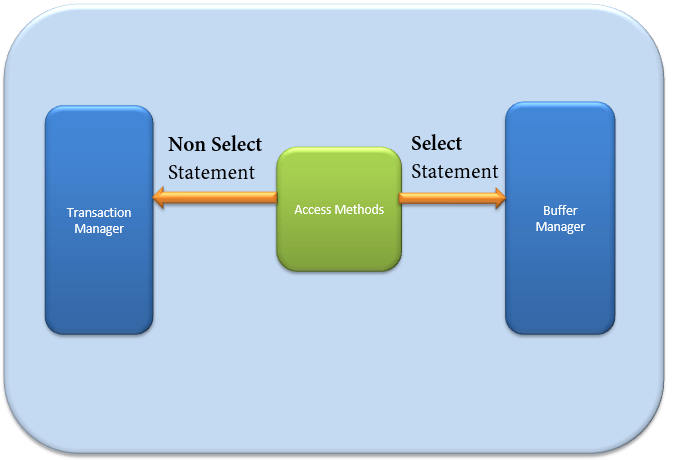
访问方法
它充当查询执行器与缓冲区管理器/事务日志之间的接口。
访问方法本身不执行任何操作。
第一步是确定查询是
- SELECT 语句(DDL)
- 非 SELECT 语句(DDL 和 DML)
根据结果,访问方法执行以下步骤
- 如果查询是DDL,SELECT 语句,则将查询传递给缓冲区管理器进行进一步处理。
- 如果查询是DDL,非 SELECT 语句,则将查询传递给事务管理器。这主要包括 UPDATE 语句。
缓冲区管理器
缓冲区管理器为以下模块管理核心功能
- 计划缓存
- 数据解析:缓冲区缓存和数据存储
- 脏页
在本节中,我们将学习计划、缓冲区和数据缓存。我们将在事务部分介绍脏页。
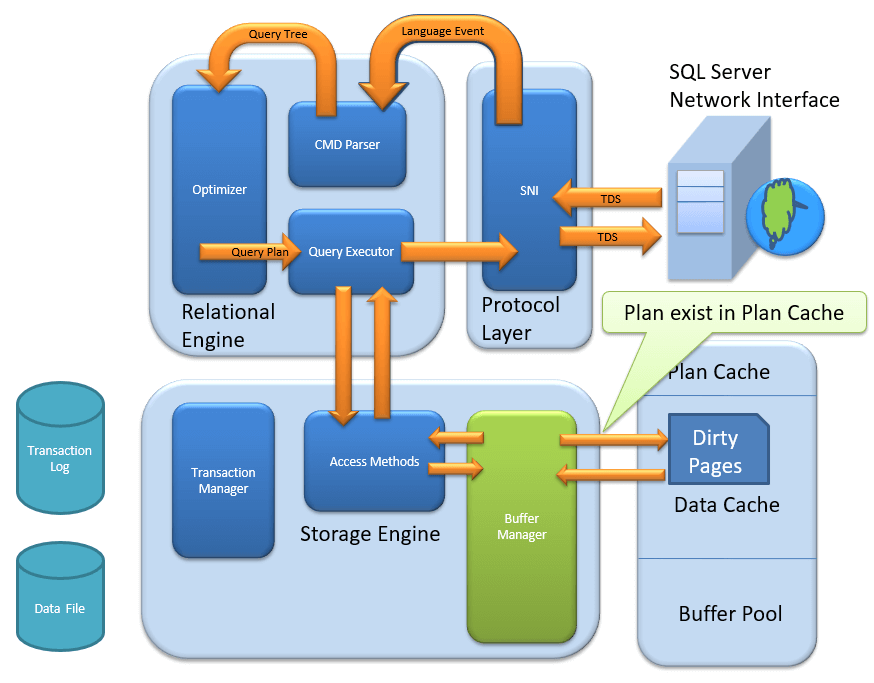
计划缓存
- 现有查询计划:缓冲区管理器检查执行计划是否在存储的计划缓存中。如果是,则使用查询计划缓存及其相关数据缓存。
- 首次缓存计划:现有的计划缓存从何而来?如果是首次执行查询计划,并且该计划很复杂,那么将其存储在计划缓存中是有意义的。这将确保下次 SQL Server 收到相同的查询时可以更快地访问。所以,它无非是执行计划的查询本身,如果是第一次运行的话。
数据解析:缓冲区缓存和数据存储
缓冲区管理器提供对所需数据的访问。根据数据是否存在于数据缓存中,可以采取以下两种方法
缓冲区缓存 – 软解析
缓冲区管理器在数据缓存中查找数据。如果存在,则查询执行器使用该数据。这提高了性能,因为与从数据存储中获取数据相比,从缓存中获取数据时 I/O 操作的数量更少。
数据存储 – 硬解析
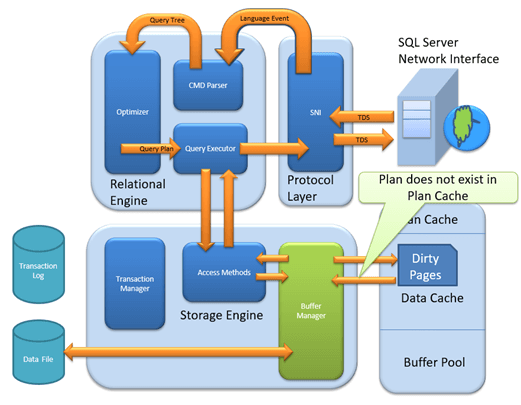
如果数据不存在于缓冲区管理器中,则在数据存储中搜索所需数据。它还将数据存储在数据缓存中以供将来使用。
脏页
它作为事务管理器的处理逻辑存储。我们将在事务管理器部分详细学习。
事务管理器

当访问方法确定查询是非 Select 语句时,将调用事务管理器。
日志管理器
- 日志管理器通过事务日志中的日志跟踪系统中的所有更新。
- 日志包含日志序列号、事务 ID 和数据修改记录。
- 这用于跟踪已提交事务和回滚事务。
锁管理器
- 在事务期间,数据存储中的相关数据处于锁定状态。此过程由锁管理器处理。
- 此过程可确保数据一致性和隔离性。也称为 ACID 属性。
执行过程
- 日志管理器开始记录,锁管理器锁定相关数据。
- 数据的副本维护在缓冲区缓存中。
- 将要更新的数据副本维护在日志缓冲区中,并且所有事件都会更新数据缓冲区中的数据。
- 存储数据的页也称为脏页。
- 检查点和写前日志:此过程运行并将所有页面从脏页标记到磁盘,但页面保留在缓存中。频率大约为每分钟运行一次。但是页面首先从缓冲区日志推送到日志数据页。这就是所谓的写前日志。
- 惰性写入器:脏页可以保留在内存中。当 SQL Server 观察到高负载并且缓冲区内存需要用于新事务时,它会从缓存中释放脏页。它操作于LRU(最近最少使用)算法,以从缓冲区池中清理页面到磁盘。
摘要
- 存在三种客户端服务器架构:1) 共享内存 2) TCP/IP 3) 命名管道
- TDS 由 Sybase 开发,现归 Microsoft 所有,它是一种封装在网络数据包中的数据包,用于从客户端到服务器的数据传输。
- 关系引擎包含三个主要组件:CMD 解析器:负责语法和语义错误,并最终生成查询树。优化器:优化器的作用是找到最便宜的、不是最好的、成本效益最高的执行计划。
查询执行器:查询执行器调用访问方法并提供执行所需数据获取逻辑的执行计划。
- 存在三种文件:主文件、辅助文件和日志文件。
- 存储引擎:包含以下重要组件访问方法:此组件确定查询是 Select 语句还是非 Select 语句。相应地调用缓冲区和传输管理器。缓冲区管理器:缓冲区管理器为计划缓存、数据解析和脏页管理核心功能。
事务管理器:它通过日志和锁管理器管理非 Select 事务。此外,它还实现了写前日志和惰性写入器的重要功能。