HANA 中的 SAP DS(数据服务)
什么是 SAP Data Services?
SAP Data Services 是一款 ETL 工具,可为数据集成、转换、数据质量、数据分析和文本数据处理提供单一的企业级解决方案,将异构源数据导入目标数据库或数据仓库。
我们可以通过 Designer 创建应用程序(作业),在其中完成数据映射和转换。(SAP BODS 的最新版本是 4.2)。
Data Services 的特性
- 它提供高性能的并行转换。
- 它具有全面的管理工具和报告工具。
- 它支持多用户。
- SAP BODS 对基于 Web 服务的应用程序非常灵活。
- 它允许使用具有丰富功能集的脚本语言。
- Data Services 可以与 SAP LT Replication Server (SLT) 集成,采用基于触发器的技术。SLT 为每个 SAP 或非 SAP 源表添加增量功能,允许对更改进行数据捕获并传输源表的增量数据。
- 通过仪表板和流程审计进行数据验证。
- 具有调度功能和监控/仪表板的管理工具。
- 调试和内置的数据分析与查看。
- SAP BODS 支持广泛的源和目标。
- 任何应用程序(例如 SAP)。
- 任何具有批量加载和更改数据捕获的数据库。
- 文件:固定宽度、逗号分隔、COBOL、XML、Excel。
Data Services 的组件
SAP DATA Services 具有以下组件:
- Designer – 它是一个开发工具,通过它我们可以创建、测试和执行填充数据仓库的作业。它允许开发人员通过在源到目标流图中选择一个图标来创建和配置对象。它可用于通过指定工作流和数据流来创建应用程序。要打开 Data Service Designer,请转到开始菜单 -> 所有程序 -> SAP Data Services(此处为 4.2)-> Data Service Designer。

- Job Server – 它是一个应用程序,用于启动 Data Services 处理引擎,并作为引擎和 Data Services Suite 的接口。
- Engine – Data Service 引擎执行应用程序中定义的单个作业。
- Repository – Repository 是一个数据库,用于存储 Designer 预定义对象和用户定义对象(源和目标元数据、转换规则)。Repository 有两种类型:
- 本地 Repository (由 Designer 和 Job Server 使用)。
- 中央 Repository (用于对象共享和版本控制)。
- Access Server – Access Server 在 Web 应用程序、Data Services Job Server 和引擎之间传递消息。
- Administrator – Web Administrator 提供基于浏览器的 Data Services 资源管理,详细信息如下:
- 配置、启动和停止实时服务。
- 调度、监控和执行批量作业。
- 配置 Job Server、Access Server 和 Repository 使用情况。
- 管理用户。
- 通过 Web 服务发布批量作业和实时服务。
- 配置和管理适配器。
Data Services 架构 –
Data Services 架构包含以下组件:
- 中央存储库 – 用于存储库到作业服务器的配置、安全管理、版本控制和对象共享。
- 设计器 – 用于创建项目、作业、工作流、数据流和运行。
- 本地存储库(您可以在其中创建、更改和启动作业、工作流、数据流)。
- 作业服务器和引擎 – 它管理作业。
- 访问服务器 – 用于执行开发人员在存储库中创建的实时作业。
在下图中,展示了 Data Services 及其组件之间的关系。
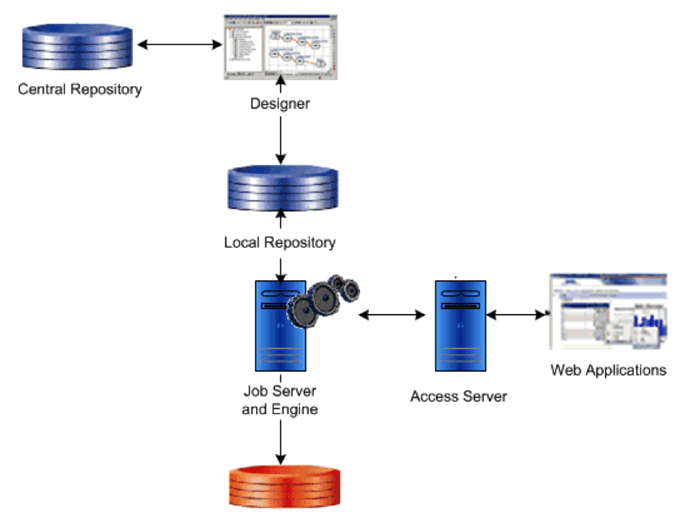
SAP BODS 架构
Designer 窗口详情: 我们首先来看 SAP 数据服务的第一个组件——Designer。
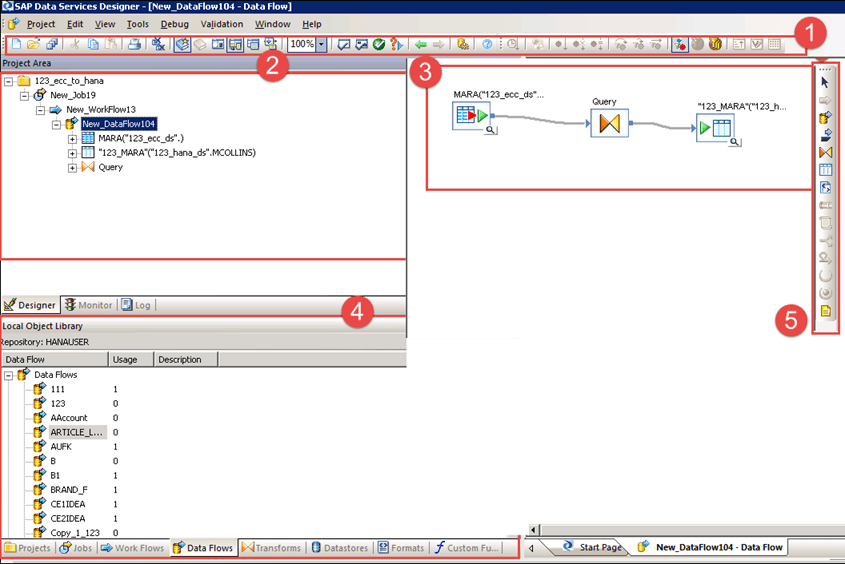
数据服务设计器各部分的详细信息如下:
- 工具栏 (用于打开、保存、后退、验证、执行等)。
- 项目区域 (包含当前项目,包括作业、工作流和数据流。在 Data Services 中,所有实体都是对象)。
- 工作空间 (我们定义、显示和修改对象的应用程序窗口区域)。
- 本地对象库 (包含本地存储库对象,如转换、作业、工作流、数据流等)。
- 工具调色板 (工具调色板上的按钮使您能够向工作区添加新对象)。
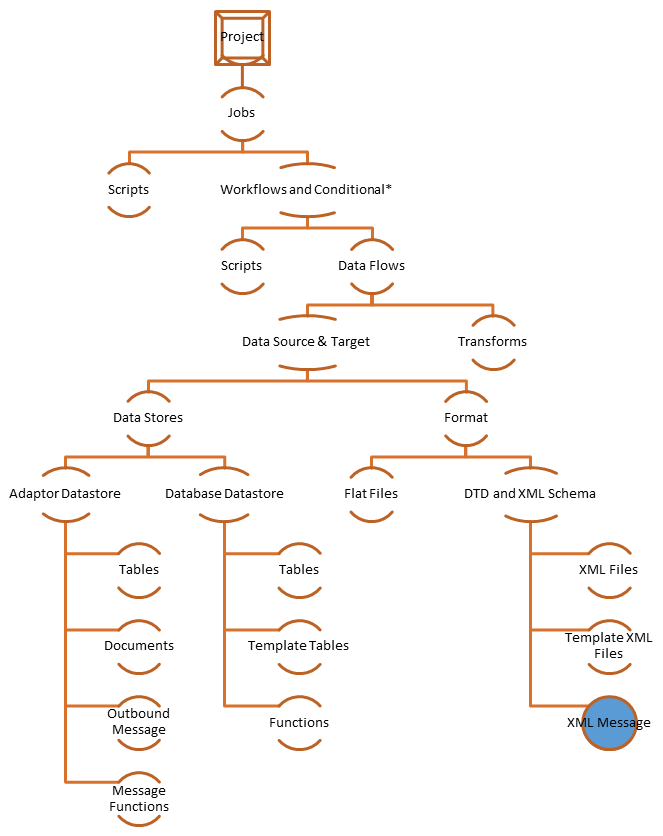
对象层次结构
下图显示了 Data Services 中关键对象类型的层次关系。
 >
>
注意

工作流和条件*是可选的
SAP Data Services 中使用的对象详情如下:
| 对象 | 描述 |
|---|---|
| 项目 | 项目是 Designer 窗口中的最高级别对象。项目为您提供了一种组织在 Data Services 中创建的其他对象的方式。一次只能打开一个项目(其中“打开”表示“在项目区域中可见”)。 |
| 作业 | “作业”是您可以独立调度执行的最小工作单元。 |
| 脚本 | 一个过程中的几行代码子集。 |
| 工作流 | “工作流”是将多个数据流整合到一个整个作业的连贯工作流中。工作流是可选的。工作流是一个过程。
|
| 数据流 | “数据流”是将源数据转换为目标数据的过程。数据流是可重用对象。它总是从工作流或作业中调用。
|
| 数据存储 | 连接 Data Services 到源和数据存储目标数据库的逻辑通道。
|
| 目标(Target) | Data Services 从源加载数据到其中的表或文件。 |
通过从 SAP 源表加载数据进行 Data Services 示例
Data Services 中的一切都是对象。我们需要为每个源和目标数据库分离数据存储。
从 SAP 源表加载数据的步骤 – SAP BODS 有许多步骤,其中我们需要为源和目标创建数据存储并将其映射。
- 在源和 BODS 之间创建数据存储
- 将元数据(结构)导入 BODS。
- 配置导入服务器
- 将元数据导入 HANA 系统。
- 在 BODS 和 HANA 之间创建数据存储。
- 创建项目。
- 创建作业(批量/实时)
- 创建工作流
- 创建数据流
- 在数据流中添加对象
- 执行作业
- 在 HANA 中检查数据预览
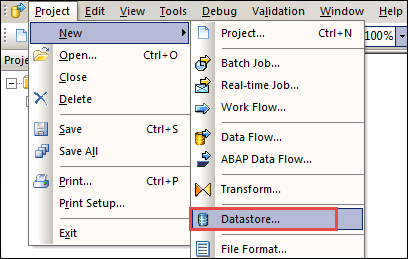
步骤 1) 在 SAP Source 和 BODS 之间创建数据存储
- 要通过 SAP BODS 将数据从 SAP Source 加载到 SAP HANA,我们需要一个数据存储。因此,我们首先创建一个数据存储,如下所示:项目 -> 新建 -> 数据存储

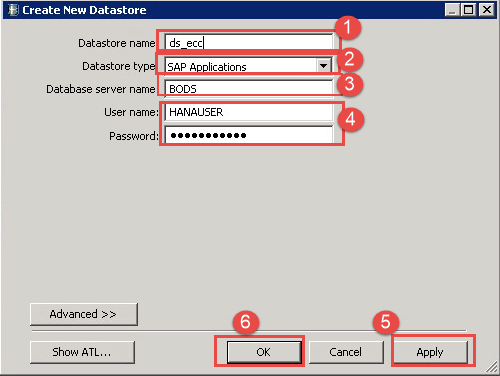
- 将出现一个“创建新数据存储”的弹出窗口,输入详细信息如下:
- 输入数据存储名称“ds_ecc”。
- 选择数据存储类型名称为“SAP Applications”。
- 输入数据库服务器名称。
- 用户名和密码。
- 单击“应用”按钮。
- 单击“确定”按钮。

- 数据存储将被创建并显示如下:
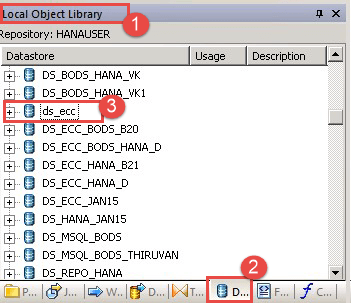
- 转到本地对象库
- 选择“数据存储”选项卡。
- 将显示数据存储“ds_ecc”。
步骤 2) 将元数据(结构)导入 BODS Server。
我们已经为 ECC 到 BODS 创建了一个数据存储;现在我们从 ECC 将元数据导入 BODS。要导入,请按照以下步骤操作:
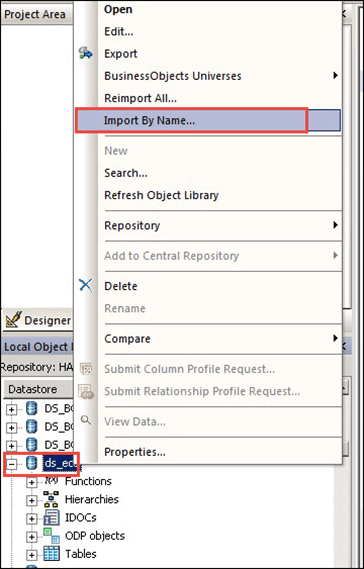
- 选择数据存储“ds_ecc”并右键单击。
- 选择“按名称导入”选项。

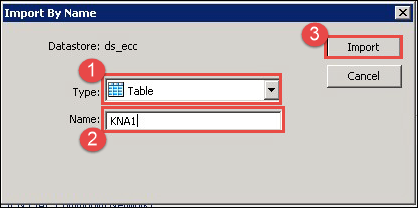
将显示一个“按名称导入”的弹出窗口。输入详细信息如下:
- 选择类型为表。
- 输入我们要导入的表名。此处我们导入 KNA1 表。
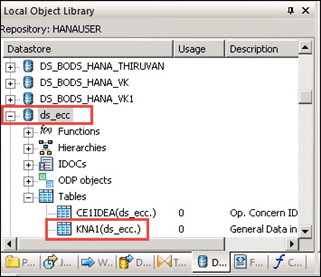
- 单击“导入”按钮。KNA1 表将显示在“ds_ecc”数据源的表节点下。

表元数据将导入到数据存储 ds_ecc 中,如下所示:
步骤 3) 配置导入服务器
到目前为止,我们已将表导入为 ECC 到 SAP BODS 连接创建的数据存储“ds_ecc”。要将数据导入SAP HANA,我们需要配置导入服务器。
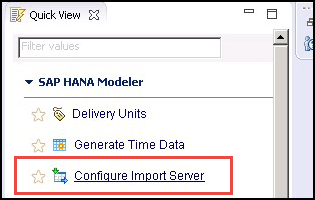
- 为此,请转到快速视图 -> 配置导入服务器,如下所示:

- 将出现一个“选择系统”的弹出窗口,选择 SAP HANA (此处为 HDB) 系统,如下所示:
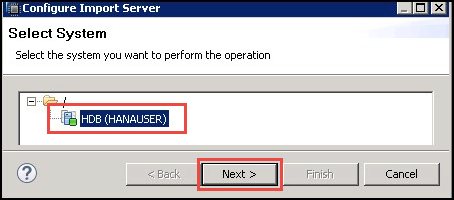
- 点击“下一步”按钮。将出现另一个弹出窗口,用于输入数据服务凭据,输入以下详细信息:
- SAP BODS 服务器地址(此处为 BODS:6400)
- 输入 SAP BODS 存储库名称(HANAUSER 存储库名称)
- 输入 ODBC 数据源 (ZTDS_DS)。
- 输入 SAP BODS 服务器的默认端口 (8080)。
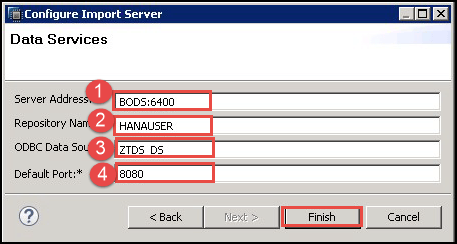
单击“完成”按钮。
步骤 4) 将元数据导入 HANA 系统
1. 到目前为止,我们已经配置了导入服务器,现在我们将从 SAP BODS 服务器导入元数据。
- 在快速视图中单击“导入”选项。
- 将显示一个“导入选项”的弹出窗口。选择“元数据选择性导入”选项。
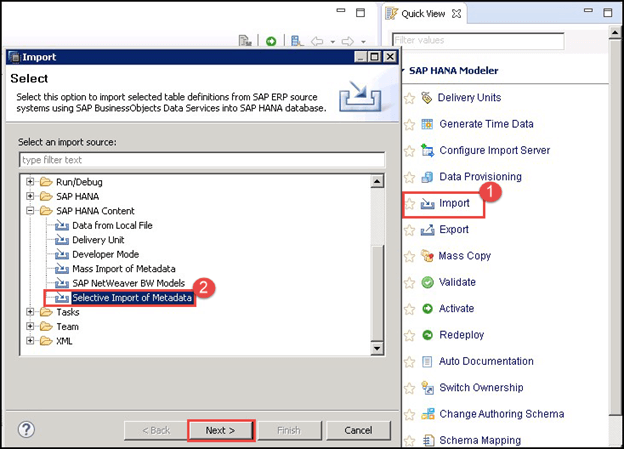
点击“下一步”按钮。
2. 将显示一个“元数据选择性导入”的弹出窗口,在其中我们选择目标系统。
- 选择 SAP HANA 系统(此处为 HDB)。
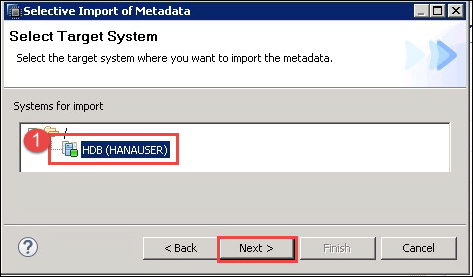
点击“下一步”按钮。
步骤 5) 在 BODS 和 HANA 之间创建数据存储
我们知道,在 BODS 中,我们需要为源和目标创建单独的数据存储。我们已经为源创建了数据存储,现在我们需要为目标(BODS 和 HANA 之间)创建一个数据存储。因此,我们创建一个名为“DS_BODS_HANA”的新数据存储。
- 转到项目 -> 新建 -> 数据存储。
- 将出现“创建新数据存储”屏幕,如下所示。
- 输入数据存储名称 (DS_BODS_HANA)。
- 将数据存储类型输入为数据库。
- 将数据库类型输入为 SAP HANA。
- 选择数据库版本。
- 输入 SAP HANA 数据库服务器名称。
- 输入 SAP HANA 数据库的端口名称。
- 输入用户名和密码。
- 勾选“启用自动数据传输”。
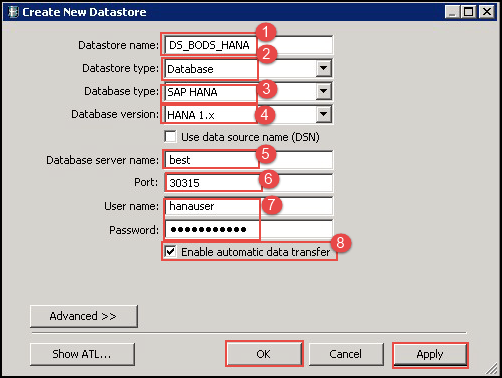
点击“应用”按钮,然后点击“确定”按钮。
数据存储“DS_BODS_HANA”将显示在本地对象库的数据存储选项卡下,如下所示:
在下面-
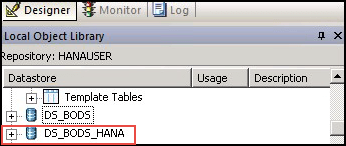
- 现在我们将表导入数据存储“DS_BODS_HANA”。
- 选择数据存储“DS_BODS_HANA”并右键单击。
- 选择“按名称导入”。
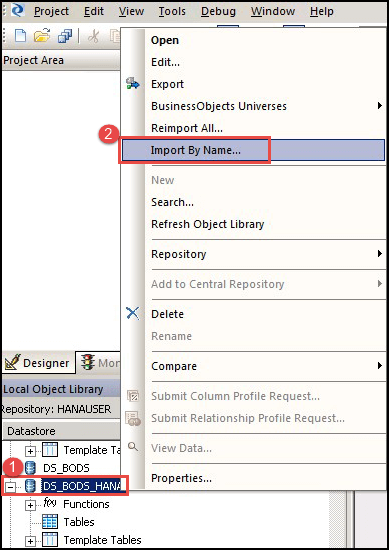
- 将出现“按名称导入”的弹出窗口,如下所示:
- 选择类型为“表”。
- 输入名称为 KNA1。
- 所有者将显示为 Hanauser。
- 单击“导入”按钮。
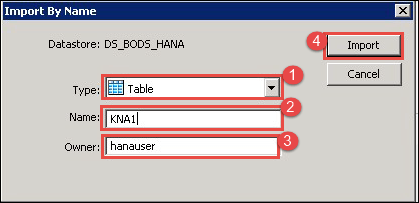
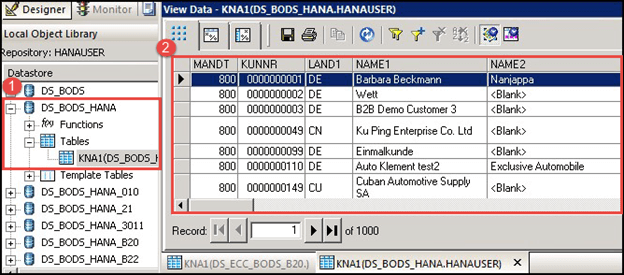
表将导入到“DS_BOD_HANA”数据存储中,要查看表中的数据,请按照以下步骤操作:
- 点击数据存储“DS_BODS_HANA”中的表“KNA1”。
- 数据将以表格格式显示。
步骤 6) 定义项目: 项目组和组织相关对象。项目可以包含任意数量的作业、工作流和数据流。
- 转到 Designer 项目菜单。
- 选择新选项。
- 选择项目选项。
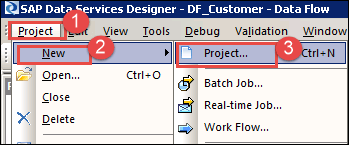
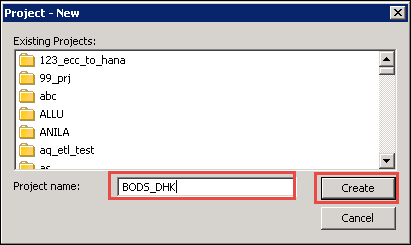
将出现一个用于创建新项目的弹出窗口,如下所示。输入项目名称并单击“创建”按钮。它将创建一个项目文件夹,在本例中为 BODS_DHK。
步骤 7) 定义作业: 作业是可重用对象。它包含工作流和数据流。作业可以手动执行或按计划执行。要执行 BODS 流程,我们需要定义作业。
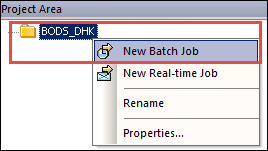
我们创建一个名为 JOB_Customer 的作业。
- 选择在步骤 1 中创建的项目 (BODS_DHK),右键单击并选择“新建批量作业”。

- 将其重命名为“JOB_Customer”。
步骤 8) 定义工作流
- 在项目区域中选择作业“JOB_Customer”,
- 点击工具调色板上的工作流按钮。点击黑色工作区区域。工作流图标将出现在工作区中。
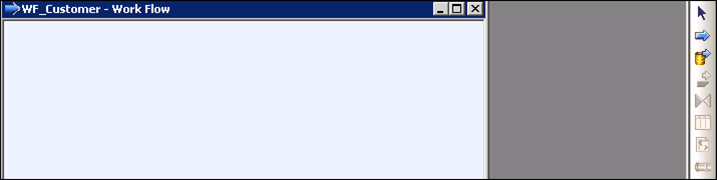
- 将工作流名称更改为“WF_Customer”。

点击工作流名称,工作流的空白视图将出现在工作区中。
步骤 9) 定义数据流
- 点击工作流“WF_Customer”。
- 点击工具调色板上的数据流按钮。点击黑色工作区区域。数据流图标将出现在工作区中。
- 将数据流名称更改为“DF_Customer”。
- 数据流也会显示在左侧项目区域的作业名称下方。

步骤 10) 在数据流中添加对象
在数据流中,我们可以提供指令将源数据转换为目标表所需的格式。
我们将看到以下对象 –
- 源对象。
- 目标表的对象。
- 用于查询转换的对象。(查询转换将列从源映射到目标。)点击数据流 DF_Customer。将出现一个空白工作区,如下所示 –


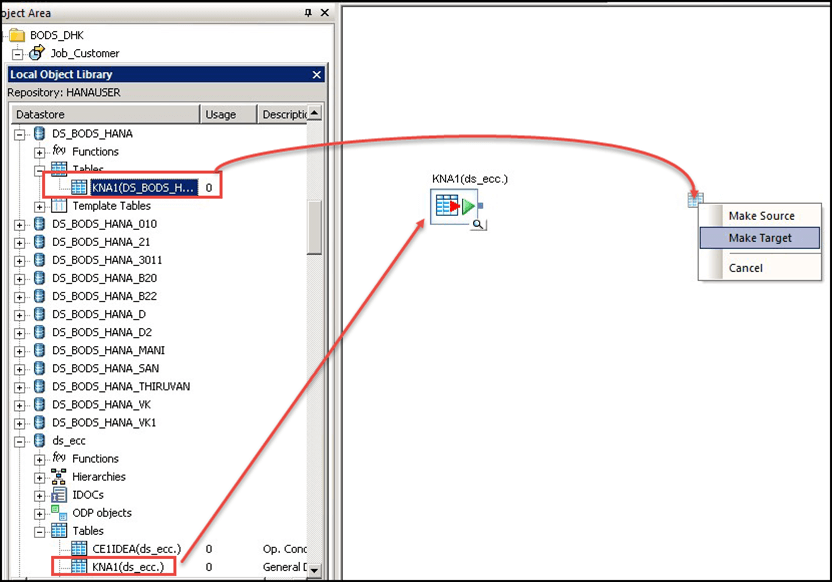
- 指定源对象 – 转到数据存储“ds_ecc”,选择表 KNA1 并将其拖放到数据流空白屏幕,如下所示:
- 指定目标对象 - 从存储库中选择数据存储“DS_BODS_HANA”,并选择表 KNA1。
- 拖放到工作区并选择“设为目标”选项。将有两个表用于源和目标。在此处我们将表定义为源和目标。
- 查询转换 – 这是一个工具,用于根据用户特定条件的输入模式检索数据,并将数据从源传输到目标。
- 从工具调色板中选择“查询转换”图标,并将其拖放到工作区中源对象和目标对象之间,如下所示 –
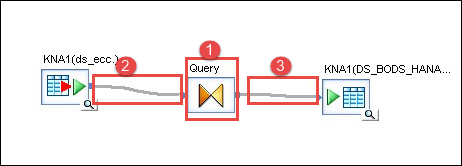
- 将查询对象链接到源。
- 将查询对象链接到目标表。

- 双击查询图标。通过此操作,我们将输入模式中的列映射到输出模式。
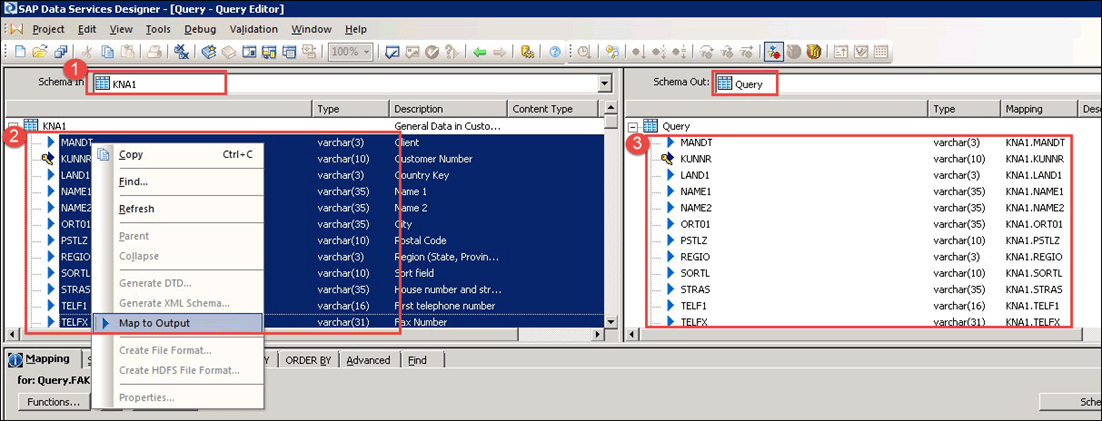
当我们点击查询图标时,将出现下一个映射窗口,我们将在其中执行以下步骤:
- 源表 KNA1 被选中。
- 从源表中选择所有列,右键单击并选择“映射到输出”。
- 目标输出选择为查询,列将被映射。
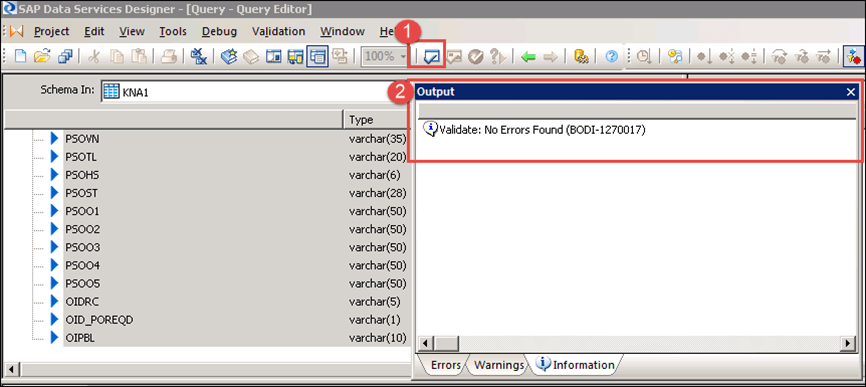
5. 保存并验证项目。
1. 点击验证图标。
2. 出现验证成功的弹出窗口。
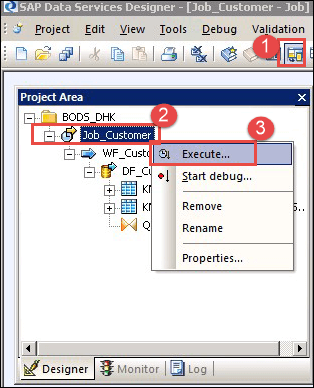
步骤 11) 执行作业 – 要执行作业,请按照以下路径操作:
- 选择“项目区域”图标以打开项目,并选择已创建的项目。
- 选择作业并右键单击。
- 选择“执行”选项,以执行作业。

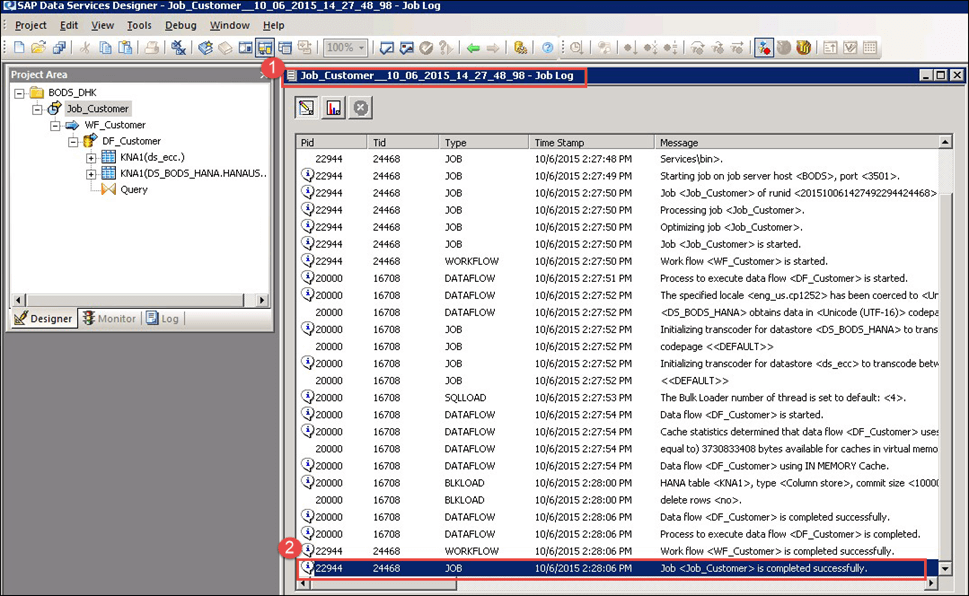
- 执行作业后,将显示一个“作业日志”窗口,其中显示所有与作业相关的消息。
- 最后一条消息将是“作业 < > 已成功完成”。

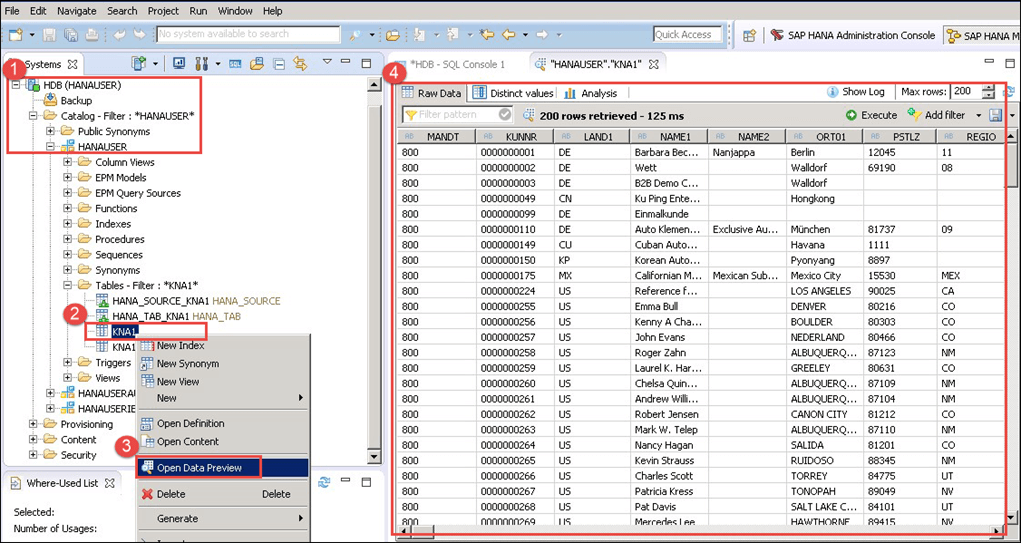
步骤 12) – 在 SAP HANA 数据库中验证/检查数据。
- 通过 SAP HANA Studio 登录到 SAP HANA 数据库,并选择 HANAUSER 模式。
- 在表节点中选择 KNA1 表。
- 右键单击表 KNA1 并选择“打开数据预览”。
- 如上所述,通过 BODS 进程加载的表 (KNA1) 数据将显示在数据预览屏幕中。