Selenium 中的链接文本和部分链接文本
Selenium 中的链接文本是什么?
Selenium 中的链接文本用于识别网页上的超链接。它通过锚标签确定。为了在网页上创建超链接,我们可以使用锚标签后跟链接文本。
匹配条件的链接
链接可以通过链接文本的精确匹配或部分匹配来访问。下面的示例提供了存在多个匹配项的场景,并解释了 WebDriver 将如何处理它们。
在本教程中,我们将学习使用 Webdriver 查找和访问链接的可用方法。此外,我们将讨论访问链接时遇到的一些常见问题,并进一步讨论如何解决它们。
Selenium 中的完整链接文本 – By.linkText()
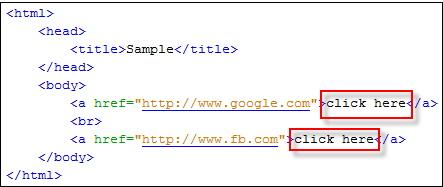
通过其精确的链接文本访问链接是通过 By.linkText() 方法完成的。但是,如果存在两个链接具有完全相同的链接文本,此方法将只访问第一个链接。请看下面的 HTML 代码
.png)
当您尝试运行下面的 WebDriver 代码时,您将访问第一个“点击此处”链接
.png)
代码
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class MyClass {
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/link.html";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
driver.findElement(By.linkText("click here")).click();
System.out.println("title of page is: " + driver.getTitle());
driver.quit();
}
}
工作原理如下:

结果,您将自动被带到 Google。
.png)
Selenium 中的完整部分链接文本 – By.partialLinkText()
使用链接文本的一部分访问链接是通过 By.partialLinkText() 方法完成的。如果您指定的部分链接文本有多个匹配项,则只访问第一个匹配项。请看下面的 HTML 代码。
.png)
.png)
当您执行下面的 WebDriver 代码时,您仍将被带到 Google。
.png)
代码
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class P1 {
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/accessing-link.html";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
driver.findElement(By.partialLinkText("here")).click();
System.out.println("Title of page is: " + driver.getTitle());
driver.quit();
}
}
.png)
如何获取具有相同链接文本的多个链接
那么,如何解决上述问题呢?在存在多个具有相同链接文本的链接,并且我们希望访问除第一个之外的链接的情况下,我们该如何处理?
在这种情况下,通常使用不同的定位器,例如 By.xpath()、By.cssSelector() 或 By.tagName()。
最常用的是 By.xpath()。它是最可靠的,但它看起来复杂且不可读。
链接文本的区分大小写

By.linkText() 和 By.partialLinkText() 的参数都是区分大小写的,这意味着大小写很重要。例如,在 Mercury Tours 的主页上,有两个包含文本“egis”的链接——一个是顶部菜单中的“REGISTER”链接,另一个是页面右下角的“Register here”链接。
.png)
尽管这两个链接都包含字符序列“egis”,但其中一个“By.partialLinkText()”方法将根据字符的大小写分别访问这两个链接。请看下面的示例代码。
.png)
代码
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/newtours/";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
String theLinkText = driver.findElement(By
.partialLinkText("egis"))
.getText();
System.out.println(theLinkText);
theLinkText = driver.findElement(By
.partialLinkText("EGIS"))
.getText();
System.out.println(theLinkText);
driver.quit();
}
块外部和内部的链接
最新的 HTML5 标准允许将 <a> 标签放置在块级标签(如 <div>、<p> 或 <h3>)的内部和外部。“By.linkText()”和“By.partialLinkText()”方法可以访问位于这些块级元素外部和内部的链接。请看下面的 HTML 代码。
.png)
.png)
下面的 WebDriver 代码使用 By.partialLinkText() 方法访问这两个链接。
.png)
代码
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class MyClass {
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/block.html";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
driver.findElement(By.partialLinkText("Inside")).click();
System.out.println(driver.getTitle());
driver.navigate().back();
driver.findElement(By.partialLinkText("Outside")).click();
System.out.println(driver.getTitle());
driver.quit();
}
}
上面的输出确认这两个链接都已成功访问,因为它们各自的页面标题已正确检索。
摘要
- 使用 click() 方法访问链接。
- 除了任何 WebElement 可用的定位器之外,链接还具有基于链接文本的定位器
- By.linkText() – 根据作为参数提供的链接文本的精确匹配来定位链接。
- By.partialLinkText() – 根据链接文本的部分文本匹配来定位链接。
- 上述两个定位器都区分大小写。
- 如果存在多个匹配项,By.linkText() 和 By.partialLinkText() 将只选择第一个匹配项。在存在多个具有相同链接文本的链接的情况下,使用基于 xpath、CSS 的其他定位器。
- findElements() & By.tagName(“a”) 方法查找页面中所有与定位器条件匹配的元素
- 无论链接在块级元素内部还是外部,都可以通过 By.linkText() 和 By.partialLinkText() 访问。