Cassandra 数据模型及简单数据库示例
尽管 Cassandra 查询语言类似于 SQL 语言,但它们的数据建模方法却完全不同。
在 Cassandra 中,糟糕的数据模型会降低性能,尤其是在用户尝试将 RDBMS 概念应用于 Cassandra 时。最好牢记以下几个详细规则。
Cassandra 数据模型规则
在 Cassandra 中,写入操作并不昂贵。Cassandra 不支持 joins、group by、OR 子句、聚合等。因此,您必须以一种可以完全检索数据的方式存储数据。因此,在 Cassandra 中建模数据时,必须牢记这些规则。
最大化写入次数
在 Cassandra 中,写入操作非常便宜。Cassandra 针对高写入性能进行了优化。因此,请尝试最大化您的写入次数以获得更好的读取性能和数据可用性。数据写入和数据读取之间存在权衡。因此,通过最大化数据写入次数来优化您的数据读取性能。
最大化数据重复
数据反规范化和数据重复是 Cassandra 的默认设置。磁盘空间不像内存、CPU 处理和 IO 操作那样昂贵。由于 Cassandra 是分布式数据库,因此数据重复提供了即时的数据可用性,并且没有单点故障。
Cassandra 数据建模目标
在 Cassandra 中建模数据时,您应该实现以下目标
均匀分布集群中的数据
您希望在 Cassandra 集群 的每个节点上有相等的数据量。数据根据分区键(主键的第一部分)分布到不同的节点。因此,尝试选择整数作为主键,以在集群中均匀分布数据。
在查询数据时最小化读取的分区数
分区是具有相同分区键的记录组。当发出读取查询时,它会从不同分区的不同节点收集数据。
如果分区很多,那么需要访问所有这些分区来收集查询数据。
这并不意味着不应创建分区。如果您的数据量很大,您无法将大量数据保存在单个分区中。单个分区会变慢。
因此,尽量选择一个平衡数量的分区。
Cassandra 中的良好主键
让我们举个例子,找出哪个主键更好。
这是 MusicPlaylist 表。
Create table MusicPlaylist
(
SongId int,
SongName text,
Year int,
Singer text,
Primary key(SongId, SongName)
);
在上面的 MusicPlaylist 表示例中,
- Songid 是分区键,
- SongName 是聚类列
- 数据将根据 SongName 进行聚类。只会创建一个包含 SongId 的分区。MusicPlaylist 表中不会有其他分区。
由于主键不佳,此数据模型的检索速度会很慢。
这是另一个 MusicPlaylist 表。
Create table MusicPlaylist
(
SongId int,
SongName text,
Year int,
Singer text,
Primary key((SongId, Year), SongName)
);
在上面的 MusicPlaylist 表示例中,
- Songid 和 Year 是分区键,
- SongName 是聚类列。
- 数据将根据 SongName 进行聚类。在此表中,每年都会创建一个新分区。该年份的所有歌曲都将在同一个节点上。这个主键对数据将非常有用。
通过此数据模型,我们的数据检索将很快。
在 Cassandra 中建模数据
在建模查询时应牢记以下几点
确定您想要支持的查询
首先,确定您想要什么查询。
例如,您需要吗?
- 联接
- 分组依据
- 在哪个列上过滤等。
根据您的查询创建表
根据您的查询创建表。创建一个能够满足您查询的表。尝试以需要读取最少分区的方式创建表。
处理 Cassandra 中的一对一关系
一对一关系意味着两个表之间存在一对一的对应关系。例如,学生只能注册一门课程,而我想查询一个学生在哪门课程中注册。
因此,在这种情况下,您的表架构应包含与该特定课程对应的所有学生详细信息,如课程名称、学生学号、学生姓名等。

Create table Student_Course
(
Student rollno int primary key,
Student_name text,
Course_name text,
);
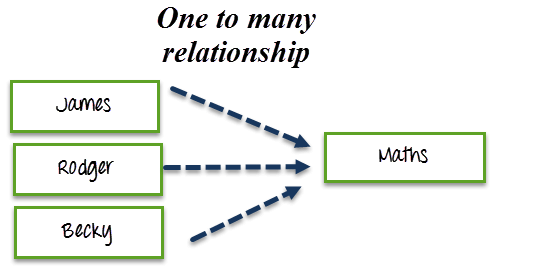
处理 Cassandra 中的一对多关系
一对多关系意味着两个表之间存在一对多的对应关系。
例如,一门课程可以被许多学生学习。我想查询所有学习特定课程的学生。
因此,通过根据课程名称查询,我将获得许多学生姓名,这些学生将学习特定课程。
Create table Student_Course
(
Student_rollno int,
Student_name text,
Course_name text,
);
我可以通过以下查询检索特定课程的所有学生。
Select * from Student_Course where Course_name='Course Name';
处理 Cassandra 中的多对多关系
多对多关系意味着两个表之间存在多对多的对应关系。
例如,一门课程可以被许多学生学习,而一个学生也可以学习许多课程。
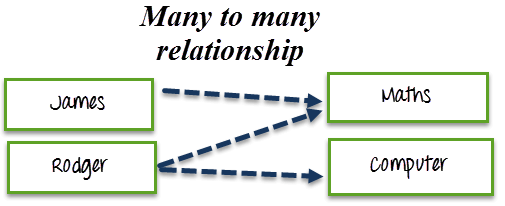
我想查询所有学习特定课程的学生。此外,我想查询一个特定学生正在学习的所有课程。
因此,在这种情况下,我将有两个表,即,将问题分为两种情况。
首先,我将创建一个表,通过它可以按特定学生查找课程。
Create table Student_Course
(
Student_rollno int primary key,
Student_name text,
Course_name text,
);
我可以通过以下查询按特定学生查找所有课程。
Select * from Student_Course where student_rollno=rollno;
其次,我将创建一个表,通过它可以查找特定课程有多少学生在学习。
Create table Course_Student
(
Course_name text primary key,
Student_name text,
student_rollno int
);
我可以通过以下查询在特定课程中查找学生。
Select * from Course_Student where Course_name=CourseName;
RDBMS 与 Cassandra 数据建模的区别
| RDBMS | Cassandra |
|---|---|
| 以规范化形式存储数据 | 以反规范化形式存储数据 |
| 传统数据库管理系统;结构化数据 | 宽行存储,动态;结构化和非结构化数据 |
摘要
- Cassandra 的数据建模与其他RDBMS 数据库不同。
- Cassandra 数据模型有一些规则。为了实现良好的数据建模,必须遵循这些规则。除了这些规则,我们还研究了三种不同的数据建模案例以及如何处理它们。
- 一对一关系意味着两个表之间存在一对一的对应关系。
- 一对多关系意味着两个表之间存在一对多的对应关系。
- 多对多关系意味着两个表之间存在多对多的对应关系。