使用 Urllib.Request 和 urlopen() 进行 Python Internet 访问
urllib 是什么?
urllib 是一个可用于打开 URL 的 Python 模块。它定义了用于 URL 操作的函数和类。
使用 Python,您还可以访问和检索互联网上的数据,如 XML、HTML、JSON 等。您还可以使用 Python 直接处理这些数据。在本教程中,我们将了解如何从网上检索数据。例如,这里我们使用了一个 guru99 视频 URL,我们将使用 Python 访问此视频 URL 并打印此 URL 的 HTML 文件。
如何使用 Urllib 打开 URL
在运行连接到互联网数据的代码之前,我们需要为 URL 库模块或“urllib”添加导入语句。
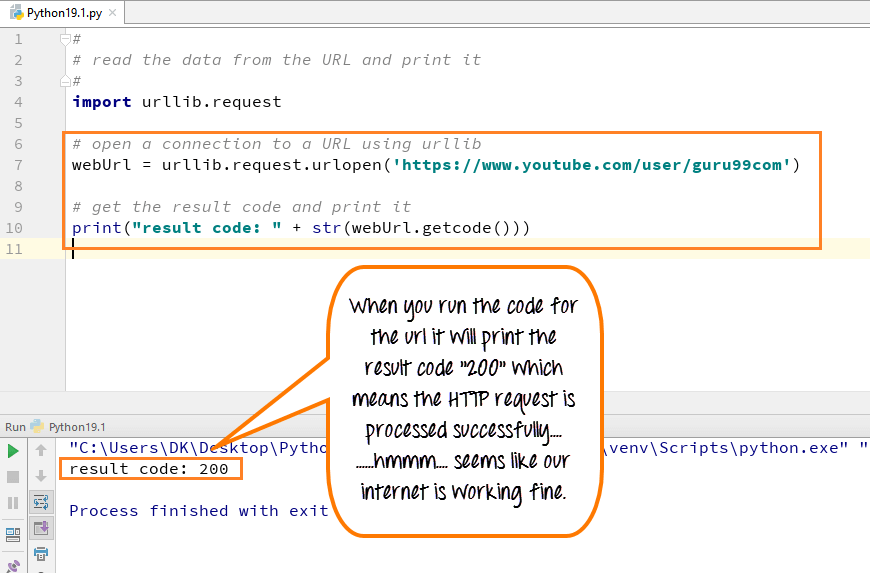
- 导入 urllib
- 定义你的主函数
- 声明 webUrl 变量
- 然后调用 urlopen 函数在 URL lib 库上
- 我们打开的 URL 是 youtube 上的 guru99 教程
- 接下来,我们将打印结果代码
- 结果代码是通过在已创建的 webUrl 变量上调用 getcode 函数来检索的
- 我们将将其转换为字符串,以便可以与我们的字符串“result code”连接
- 这将是一个常规的 HTTP 代码“200”,表示 http 请求已成功处理
如何在 Python 中获取 URL 的 HTML 文件
您还可以使用 Python 中的“read function”来读取 HTML 文件,运行代码后,HTML 文件将出现在控制台中。
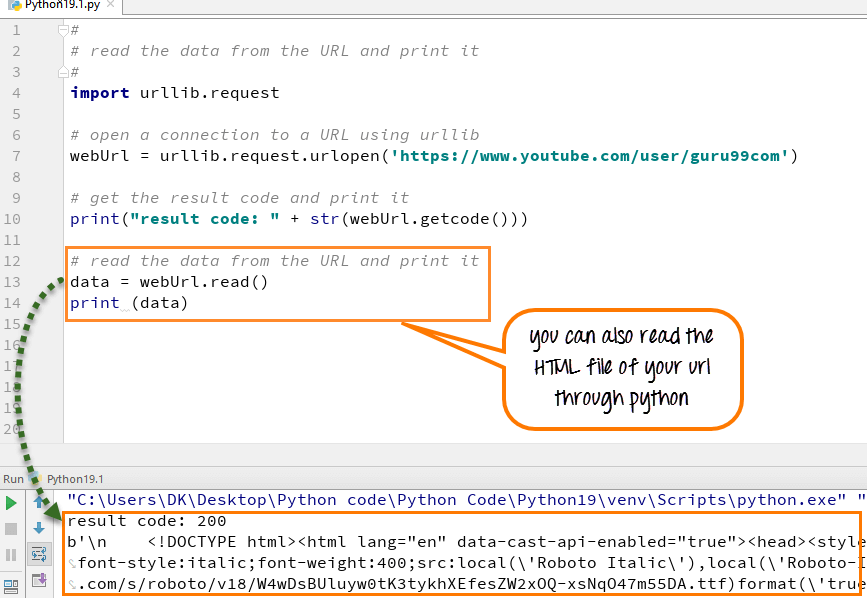
- 在 webURL 变量上调用 read 函数
- Read 变量允许读取数据文件的内容
- 将 URL 的整个内容读取到一个名为 data 的变量中
- 运行代码 - 它将以 HTML 格式打印数据
这是完整的代码
Python 2 示例
#
# read the data from the URL and print it
#
import urllib2
def main():
# open a connection to a URL using urllib2
webUrl = urllib2.urlopen("https://www.youtube.com/user/guru99com")
#get the result code and print it
print "result code: " + str(webUrl.getcode())
# read the data from the URL and print it
data = webUrl.read()
print data
if __name__ == "__main__":
main()
Python 3 示例
#
# read the data from the URL and print it
#
import urllib.request
# open a connection to a URL using urllib
webUrl = urllib.request.urlopen('https://www.youtube.com/user/guru99com')
#get the result code and print it
print ("result code: " + str(webUrl.getcode()))
# read the data from the URL and print it
data = webUrl.read()
print (data)